본 포스팅은 단기강좌 인터넷 속의 수학의 강의 들을 요약하는 포스트입니다.
Introduction
Netflix라는 미국의 DVD rental 업체가 있다. 이전 포스트에서 다뤘던 기업 중에 하나인데, 다시 한번 간략하게 설명을 하자면 Netflix는 미국의 온라인 DVD rental 업체이다. 1997년 시작한 DVD rental business이며 초기 BM은 간단했다. 한달에 고정적인 비용을 내고 video나 dvd를 빌릴 수 있도록 하며 번거로운 연체료가 없는 모델이었다. 이렇게 하면 return률이 감소하는 단점이 있는데 이런 단점을 새로운 dvd를 빌리려면 다시 return해야 빌릴 수 있는 rule을 만들어 크게 성공하였다. 디멘드를 읽어보면 이에 대해서는 자세히 알 수 있을 것이다. 이후 2007년에 VOD(video on demand) service를 시작하였고, 2008년 9 million이던 user가 VOD 이후 30 million으로 폭증하였다. 현재 미국 traffic 25%는 Netflix VOD 때문에 발생할 정도로 거대한 기업이 되었다. 이렇게 Netflix가 크게 성장하게 된 배경에는 Recommendation system이 존재하는데, Netflix의 추천 시스템은 User prior video history를 기반으로 새 영화를 추천하고 사용자들이 더 다양하고 많은 비디오를 빌려볼 수 있도록 유도하고 있다. 이런 추천시스템은 Amazon, Youtube, GeoLife in MS 등도 적용하고 있는 많은 기업들에게 중요하게 인식되고 있는 시스템이다.
잠시 본 글로 넘어가기 이전에 Recommendation, 혹은 추천이라는 문제에 대해서 잠시 생각해보고 넘어가보자. 세상에는 정말 많은 Recommendation problem이 존재한다. 정말 간단한 현실 속의 예를 들어보자면 소개팅을 예를 들 수 있다. 소개팅을 주선해 줄 때 어떤 상대를 소개시켜주는 것이 가장 적절할까? 가만 생각해보면 소개팅을 상대방과 잘 맞을 것으로 예상되는 사람을 ‘추천’ 해주는 문제로 변경해서 해결해 볼 수 있다. 예를 들어서 내가 소개팅을 시켜주려는 상대가 이전에 A라는 타입을 좋아했었다면 이번 소개팅에서도 A 타입을 추천해주는 방식으로 문제 해결이 가능한 것이다. 이런 것이 일종의 recommend question이다.
스포츠를 좋아하는 사람들을 위해 다른 예시를 들어보자면, 야구에서도 추천 문제로 생각할 수 있는 경우가 존재한다. 예를 들어서 현재 대타를 내세워야하는 상황이라고 생각해보자. 감독이 이런 중요한 순간에 A, B, C 타자 중 어떤 타자로 교체할지 decision making을 하는 것도 일종의 recommend question으로 생각이 가능하다. 예를 들어서 과거 대타 성공률을 기준으로 recommend를 하거나 아니면 출장 경기 기준 혹은 최근 몇 경기 실적 등으로 판단할 수가 있는 것이다.
이런 Recommendation problem은 Machine Learning 분야 중 굉장히 각광받고 주목받는 영역 중의 하나이다. 이 글에서는 ML의 컨셉이란 무엇인지에 대해 간략하게 다루고, 이런 recommend problem이 ML에서 어떤 positioning을 지니는지에 대해 얘기를 할 것이다.
Machine Learning
Machine Learning이란 무엇인가? 이 블로그에서 다뤘던 수 많은 글들이 Machine Learning에 대해 다루고 있지만, 역시 간략하게 다시 언급을 하자면 Machine Learning은 Data로 부터 system을 구성하는 것이라고 할 수 있다. 위키피디아의 설명을 참고하자면 ‘Machine learning, a branch of artificial intelligence, concerns the construction and study of systems that can learn from data.’ 라고 한다.
이해를 돕기 위해 사람이 새로운 정보를 습득하는 과정에 대해서 생각해보자. 학교에서 새로운 지식을 배울 때, 우리는 수업과 책을 읽고 정보를 습득한다. 그리고 내가 제대로 배웠는지 판단하기 위해서 시험을 치고 그 결과에 따라서 이 정보를 잘 습득했다, 혹은 그렇지 못했다를 판단할 수 있는 것이다. 이때 공부를 위해서 sample exam을 계속 치면서 자신의 이해도를 판단하고 자신의 공부 방법을 개선해서 더 나은 학습을 하는 것이 가능하다. (시험을 수능, sample exam을 모의고사라고 생각하면 이해가 빠를 것이다)
Machine Learning도 크게 다르지 않다. 예를 들어 spam filter를 구성하는 ML algorithm을 작성한다고 생각해보면, 이 algorithm을 사용하는 system은 사용자가 spam mail이라고 report한 기존의 정보들을 습득하고 그 정보를 기반으로 새로운 email이 spam인지 아닌지 판별을 하게 된다. 이때 제대로 판단을 했느냐 하지 못했느냐로 해당 알고리듬이 얼마나 우수한지 판별할 수 있을 것이다. 사람으로 비유를 하자면 이 과정은 수능을 쳐서 자신이 얼마나 공부했는지를 판별하는 과정과 유사하다. 알고리듬의 개선을 위해서 지속적으로 test set을 통해 알고리듬의 변수들을 조정하여 더 나은 알고리듬을 만들어낼 수 있는데, 이 과정은 사람이 모의고사로 공부를 하는 과정과 유사하다.
이렇듯 Machine Learning에서 중요한 것은 system을 학습시키는 traing data가 존재하며, 해당 data를 기반으로 system이 구성이 된 이후 training data가 아닌 새로운 data를 사용해 맞는 결과인지 아닌지를 확인하고 이 정보를 feedback해 현재 알고리듬을 개선한다. 즉, tranining data를 사용해서 ML algorithm에서 사용할 model과 rule을 만들고 test data를 사용해 해당 algorithm의 우수성을 판단하고 system을 개선시키는 것이 Machine Learning의 기본 컨셉이다.
그렇다면 왜 이제와서 Machine Learning인가? 최근 ML이 꽤 hot한 field로 주목받고 있지만, 사실 ML자체는 컨셉이 처음 나온지 벌써 2-30년이 된 생각보다 오래된 학문이다. 이런 현상이 일어나게 된 것에는 흔히 말하는 Big data의 등장이 있다. Big data가 등장함으로 인해 ML에서 가장 중요한 data가 그야말로 엄청나게 많아지고 또한 접근성도 좋아지면서 이를 통해 의미있는 무언가를 찾아내기 용이해졌다. 이런 데이터를 통해 새로운 information을 도출할 수 있다면 분명 여러 분야에서 큰 도움이 될 것으로 예상할 수 있을 것이다. 이런 motivation으로 최근 ML이 크게 각광받고 있는 상황이며 흔히 말하는 빅데이터가 사실은 ML을 의미하는 경우도 많다. 이 글에서 얘기하게 될 Netflix는 ML과 Big Data의 가장 훌륭하고 성공적인 realistic한 BM example로 손꼽히고 있다.
Recommendation Problem in Netflix
사용자의 과거 영화 열람 기록을 기반으로 영화를 추천하기 위해서는 이 문제를 풀이가 가능한 형태로 바꾸는 과정이 먼저 필요할 것이다. 여러 방법이 있을 수 있겠지만, 여기에서는 간단한 하나의 Matrix로 문제를 바꾸어서 생각해보자.
위의 matrix에서 각각의 element는 user가 movie를 rating한 결과를 의미하고 각 column은 하나의 movie를 의미하고 각 raw는 user를 의미한다고 생각해보자. 다시 말해서 맨 처음 element는 1번 user가 1번 영화에 별점을 3점을 줬다는 것을 의미한다고 생각해보자. 마찬가지로 8번 user는 4번 영화에 1점을 준 것이라고 생각할 수 있을 것이다. *은 아직 영화에 평점을 주지 않았다는 것을 의미하고, 우리의 목표는 평점이 주어지지 않은 영화에 user가 과연 평점을 어떻게 매길까를 최대한 결과와 비슷하도록 예측을 하는 것이다. (이 Matrix를 Netflix Matrix라고 하자, 참고로 이 Matrix의 크기는 user가 480,000명, movie가 18,000개 존재하는 엄청나게 큰 Matrix이며 우리가 알고 있는 데이터는 이 중에서 1% 밖에 되지 않는다고 한다.)
즉, 영화 recommendation 문제는 일부 element가 소실되어 있는 matrix의 원본을 복원하는 recovery문제로 바꾸어서 생각할 수 있는 것이다. 이제 Unknown data를 알아내기 위해 Machine learning algorithm이 필요한 것이다. 주어진 data pattern에서 알려지지 않은 새로운 데이터를 추측하는 것이니 이 역시 ML문제라고 생각할 수 있는 것이다.
당연한 얘기지만 접근 방법은 무수히 많을 것이다. 그렇다면 여기에서 궁금증이 생기는데, 과연 그 수많은 알고리듬 중 어느 알고리듬이 우수한지 어떻게 평가할 수 있을까? 여러 algorithm 중에서 가장 좋은 system을 선택하기 위한 evaluation이 필요한 것이다. 실제 정보와 차이를 기반으로 평가를 할 수도 있지만, 일일이 그렇게 평가하는 것은 꽤 어렵기 떄문에 RMSE(Root Mean Squared Error)를 사용한다. RMSE는 $\sqrt{MSE} = \sqrt{\frac 1 n \sum_{i=1}^n ( \hat{X_i}-X_i )^2}$ 로 표현이 되는데, 다시 말해서 전체 평균과 각각의 정보가 얼마나 많이 차이가 나는가를 평가하는 것이다. 당연히 RMSE는 작을수록 좋고 이 알고리듬을 evaluation하기 위해서 알고리듬의 결과로 나온 predicted result를 ground truth label과 비교하는 것이다.
Netflix Prize
Netflix는 자체 추천 알고리듬을 이미 가지고 있었지만, Netflix prize라는 것을 만들어서 이미 가지고 있는 알고리듬을 개선시키고자 하였다. 문제는 간단했다. 현재 Netflix의 recommend system의 RMSE를 10% 가량 개선시킬 수 있느냐? 문제가 2006년 10월에 공지되었으니 알고리듬은 그 당시를 기준으로 평가를 하였다. 이 prize를 위해서 1995 ~ 2005년 동안의 data를 사용해 Training set 100 million (책), probe set 1.4 million (문제집), quiz set 1.4 million (모의고사), test set 1.4 million (수능) 만큼의 data를 제공하였는데 이 정도의 데이터는 Personal Computer에서 돌릴 수 있을만큼 정도의 Data set이었다. 개발자들이 자신의 알고리듬을 평가하기 위해 하루에 한 번 정도 (Maximum 1번) Quiz set에 내 algorithm을 적용시켜 RMSE를 알 수도 있었다. ML 기법을 적용시키고 실제 RMSE를 개선시키는 것이 이 상의 목적이었고 상금은 한화로 약 10억원정도의 금액이었다.
그렇다면 과연 이 문제가 10억 이상의 가치가 있었는가라는 질문이 생길 수 있는데, 결론적으로만 말하면 그렇다고 대답할 수 있다. 일단 RMSE의 값을 0.01만 감소시켜도 top 10 recommendation이 달라질 정도로 이 값을 바꾸는 것은 실제 Netflix에 크게 영향을 미칠 수 있다. 또한 문제가 10억원을 내걸 정도로 꽤나 어려운 문제였는데, 이 문제가 완전히 풀리는데 3년이라는 시간이 걸렸으니 결코 쉬운 문제는 아니었던 것이다. 본래 Netflix가 가지고 있던 알고리듬은 Cinemath라는 고유 알고리듬이었는데, 이 알고리듬은 벌써 0.9514 RMSE를 가지고 있었다. 이 값의 10%를 개선하려면 RMSE가 0.8563보다 작은 알고리듬을 개발해야하는데, 아무 사전 지식이 없었던 참여자들이 Cinemath를 beating하는 데에 (따라잡는 데에) 겨우 1주일이 걸렸으며, 8.26%를 beating하는 데에도 겨우 10개월이라는 시간이 걸렸다. (team BellKor, 2007) 첫 해에 결국 8.43%의 결과를 달성했으며 이 값만 봐서는 정말 금방 마무리 될 것 처럼 보였으나… 0.8616까지 도달하는건 1년이 더 걸리고 (2008년) 결국 당시 leading team이던 BellKor와 BigChaos라는 팀이 결합해서 2009년 6월에 10%에 도달할 수 있었다. 여기까지 도달하는 데에 3년이라는 시간이 걸린 셈이다.
Netflix prize는 총 5000개 이상의 팀이 도전했고 quiz set이 총 44,000 번 test되었다. 가장 먼저 10%를 달성한 팀은 방금전 설명한 BellKor, BigChaos 그리고 Pragmatic Theory 세 팀의 연합 팀이었는데, 10% 달성 이후 30일의 여유 기간에서 Ensemble이라는 다른 팀이 또 10%를 달성하게 되었다. 최종 평가를 위해 알고리듬을 돌려본 결과 두 팀의 RMSE값이 같았는데, BellKor, BigChaos, Pragmatic Thoery 연합팀의 알고리듬이 20분 더 빨라서 결국 상금은 이 팀이 가져가게 되었다.
Key ideas in the winner of the prize
사실 10%를 달성하기 위한 마지막 1%에는 정말 어마어마한 efforts를 들이부어서 algorithm을 tuning한 결과이다. 하지만 10%의 performance 중 8~9% 정도의 performance improvement를 위해서는 몇 개 안되는 key idea들만을 사용해서 충분히 그 결과를 얻어낼 수 있다. 이 글에서는 크게 두 개의 아이디어를 소개할 예정이다. 하나는 Neighborhood Method이고, 또 하나는 Matrix Factorization이다.
Neighborhood Method는 각각의 영화들이 얼마나 연관성이 있으며 user끼리는 어떤 연관성이 있는가에 대한 질문에서 시작된 알고리듬이며, 방금 말한 영화 혹은 사용자 간의 유사성을 통해 사용자의 결과를 예측한다. 만약 Machine Learning 중 Clustering에 관심이 있다면 collaborative filtering과 비슷하다고 느낄텐데, 사실 거의 같은 알고리듬이라고 생각하면 된다. 이 알고리듬은 사용자들을 그룹핑하고 (pair를 만들고) 그 그룹 안에 속한 유저가 내린 rating이 다른 user와 얼마나 비슷한지 혹은 다른지 (즉 상관도가 얼마나 있는지) 측정하고 그 측정 값을 기반으로 추천을 하는 알고리듬이다. 즉, 이전에 봤었던 Netflix Matrix에서 비어있는 entry를 그 주변 entry 들의 값을 보고 복구하는 방법이라고 생각할 수 있다.
컨셉만 놓고 비교하자면 Neighborhood Method가 훨씬 간단하지만 Matrix Factorization는 이보다 더 강력한 성능을 자랑한다. 다른 알고리듬 없이 이 알고리듬만 잘 구현한다면 기존 Netflix의 성능을 8-9% 정도 개선하는 것이 가능하다. 이 알고리듬의 기본 아이디어는 크게 어렵지 않다. 이 알고리듬이 기본적으로 사람들의 type 혹은 class가 생각보다 많지 않다는 것을 가정한다. 즉, drama를 얼마나 좋아하느냐, action을 얼마나 좋아하느냐 등등의 요소들이 각 유저들의 rating을 결정한다는 의미이다. 만약 전체 점수를 S라고 하고 각 factor를 fi 라고 하고 각각의 factor마다 개인이 가지는 가중치를 ai 라고 가정하자. 그리고 전체 n개의 factor가 있다고 한다면, 한 사람이 rating하게 될 점수의 예상치를
$$ S = \sum_{i}^{n} {a_i * f_i} $$로 표현할 수 있을 것이다. 이런 몇 개의 basic classes의 combination으로 user의 rating이 표현이 될 수 있다면, Basic한 몇 개의 요소로 rating이 결정된다 라고 설명할 수도 있으며 약간 수학적으로 설명을 하자면 Netflix Matrix가 몇 안되는 factor들을 통해 표현할 수 있다는 의미가 되므로 Netflix Matrix가 low rank를 가지고 있다라고 표현할 수 있는 것이다. 이 statement가 Matrix Factorization algorithm의 기본 가정이다.
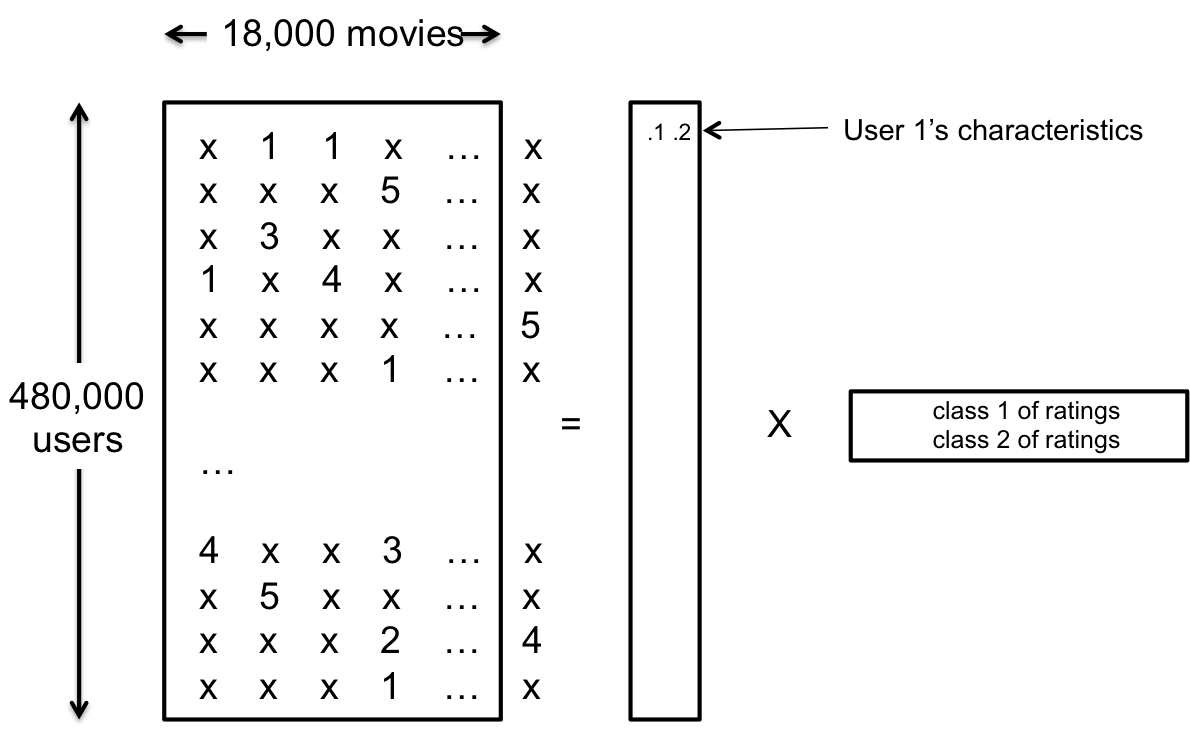
이 알고리듬의 목표는 각각의 ‘class i of ratings’ 를 알아내는 것이다. 이 알고리듬이 실제 의미가 있기 위해서는 Netflix Matrix에서 알고 있는 데이터가 어느 정도 많아야 한다. 실제로 해당 decomposed 된 matrix에 들어있는 entry보다는 많은 데이터를 알고 있어야 하는데, 위의 그림에서 우리는 18,000개의 영화와 480,000명의 유저의 정보를 2개의 class로 표현했으므로 우리가 이미 알고 있는 1%의 정보를 사용하면, 총 48000 * 18000 * 0.01개, 약 8백만개 정도의 데이터를 사용해서 2 * 48000 + 18000 * 2 개, 즉 13만 2천개의 entry를 알아내야 한다. 8백만개의 정보에서 13만 2천개의 정보를 뽑아내는 것은 데이터의 양이 충분하다고 할 수 있을 것이다. 물론 지금은 rank가 2이라고 가정했으므로 2를 곱했고 13만 2천이라는 숫자를 얻게 되었지만, 실제로는 이보다는 더 많은 rank를 가졌다고 가정하고 때문에 더 많은 정보를 알아내야하기는 하지만, 그래도 8백만개에 비하면 충분히 작은 숫자가고 할 수 있을 것이다.
이 이외에도 다양한 아이디어가 있는데 예를 들어 Implicit feedback 아이디어는 사용자가 영화를 자주 봤음에도 불구하고 rating을 하지 않은 경우에 대해서 Netflix Matrix에 반영되지 않은 implicit한 data까지 사용해서 rating을 예측하는 아이디어이며, Temporal dynamics 아이디어는 Netflix Matrix가 불변하는 static한 Matrix가 아니라 실제로는 사람마다 영화 취향이 바뀔 수 있고 매번 유행하는 영화가 바뀌는 등 temporal하게 봤을 때 dynamic한 matrix라고 가정하고, 시간 축 상에서 entry들이 변화하는 양을 measure하여 이를 rating에 반영하는 아이디어이다. 이 밖에도 다양한 아이디어들이 있고 이런 추가적인 아이디어은 실제 8~9% 이상의 무언가를 달성하기 위한 알고리듬 튜닝에 쓰였다고 한다.
이상으로 Netflix prize와 실제로 그 목표를 달성한 알고리듬의 brief한 소개를 마치도록 하겠다. 이보다 더 자세한 내용은 두 번째 글에서 다루도록 하겠다