이번에 리뷰할 논문은 Google DeepMind가 NIPS 2014에 발표한 Recurrent Neural Networ와 Reinforcement Learning을 결합한 Recurrent Models of Visual Attention 이라는 논문이다. 지난 글에서 리뷰했던 Playing Atari With Deep Reinforcement Learning과 같은 연구팀에서 진행한 연구인듯하다. Atari 논문에서는 전통적인 RL 문제인 ‘게임’을 풀기 위하여 CNN으로 action-value function을 모델링하고 value iteration을 대체하는 새로운 action-value function learning 모델과 알고리즘을 제안했다면, 이 논문은 기존 RL 문제라기보다는 오히려 좀 더 클래식한 classification 문제라고 할 수 있는 image recognition 문제에 RNN 구조와 RL 구조를 결합하여 reward maximization optimization problem을 푸는 모델과 알고리즘을 제안한다.
Motivation
CNN 기반의 image classification은 이미 인간이 할 수 있는 수준에 거의 근접하였다. 그러나 CNN을 사용한 기존 접근 방법은 input size가 fix되어있어야하고, pixel size가 엄청나게 크면 그만큼 computation cost가 그대로 늘어난다는 단점이 존재한다. 하지만 실제 사람이 물체를 인식하거나 할 때를 생각해보면, ‘attention’이 존재한다는 것을 알 수 있다. 즉, 배경을 포함한 모든 정보를 사용하여 물체를 인식하는 것이 아니라 자신이 focus하고 있는 일부분과 그 주변 부의 정보들을 ‘훑어보면서’ 훑어본 sequence들을 복합적으로 종합하여 결론을 내린다는 것을 알 수 있다. 만약 이런 방식으로 ‘focusing’을 하는 모델을 만들 수 있다면 지금 보고 있는 화면의 일부 만을 사용하므로 더 적은 ‘bandwidth’의 데이터를 저장해도 되고, 정보를 처리하기 위해 좀 더 적은 양의 pixel이 필요할 것이다. 그렇기 때문에 단순 pixel map을 파악하는 것 보다 이런 ‘atenttion’을 고려한 훨씬 더 human-like한 모델을 설계한다면 기존 CNN의 단점을 해결하는 데에 도움이 될 수 있을 것이라는 것이 이 논문의 motivation이다. 이 논문은 visual scence의 attention-based processing을 attention을 어떻게 취할 것인지를 action으로 생각하여 일종의 control problem으로 모델링하여 문제를 해결한다.
이 논문은 기존 CNN기반 approach들처럼 각 time stamp에 대해 전체 이미지를 한 번에 처리하거나 혹은 이미지 박싱을 하는 대신에 모델이 attend해야할 다음 location을 과거 정보와 현재 reward를 기반으로 선택하는 모델을 제안한다. 이 모델은 기존 CNN 모델과는 다르게 image의 크기가 바뀌더라도 computation이나 memory가 그 크기에 linear하게 증가하지 않고 모델에 의해 조절 가능하다는 특징이 있다.
The Recurrent Attention Model (RAM)
구체적인 모델을 정의하기 위하여 먼저 attention problem을 정의해보자. 이 논문은 attention problem을 visual 환경과 interact하는 목표지향적인 agent가 행하는 sequential decision process로 정의한다. 각 time stamp하다 agent는 bandwidth-limited sensor만을 사용해 environment를 observe하게 된다. 즉, agent는 한 번에 전체 environmnet를 감지하지 않고, 매 time stamp마다 local한 정보 만을 감지한다. 대신 agent는 sensor를 어떻게 사용할 것인지, 다시 말해서 sensor의 다음 location을 선택하는 action을 취할 수 있다. 마치 사람이 시선을 쭉 움직이면서 visual scence을 훑어보는 것처럼 말이다. 만약 reward를 image classification과 관련되도록 정의한다면 이런 attention 문제는 한 번에 센서가 볼 수 있는 정보가 한정되어있고, action을 어떻게 취하느냐에 따라 결과가 (reward가) 크게 달라지기 때문에 state별로 reward를 maximize하는 action을 취하는 policy를 learning하는 reinforcement learning 문제로 생각할 수 있다.
이제 모델을 조금 더 구체적으로 정의해보자.
$x_t$: agent가 time $t$에 관측한 environment (전체 image의 일부분)
$\ell_t$: agent가 time $t$에 focus하고 있는 region의 좌표 값, 실제 agent는 $\ell_t$의 주변을 관측한다. 이 값은 논문에서 sensor control의 action으로 사용된다.
$a_t$: agent의 time $t$에서의 environment action. Classification의 경우는 $a_t$가 classification을 하는 decision을 내리는 용도로 사용된다. 즉, MNIST data로 실험하는 경우 가능한 $a_t$의 경우 수는 [0-9]이며, 각각 0부터 9까지의 숫자를 나타내게 된다.
$r_t$: agent가 maximize하고자하는 목표 값이다. Image classification은 time $t$에서 정확한 classification을 했으면 reward가 1, 아니라면 reward가 0이 되도록 설정하였다고 한다.
$h_t$: time $t$에서 agent의 state를 ‘hidden’ state로 표현한 것으로, 원래 state는 $s_{1:t} = x_1, \ell_1, a_1, \ldots, x_{t-1}, \ell_{t-1}, a_{t-1}, x_t$로 표현되지만, 만약 $h_t$를 이 모든 state들을 ‘summarize’하는 것과 같이 모델링 할 수 있다면, 전체 state를 보는 대신, summerized internal state인 $h_t$로 state 표현을 대신할 수 있다.
위와 같은 모델을 설계하기 위하여 이 논문에서는 다음과 같은 RNN 형태의 neural netork model은 제안하고 있다.
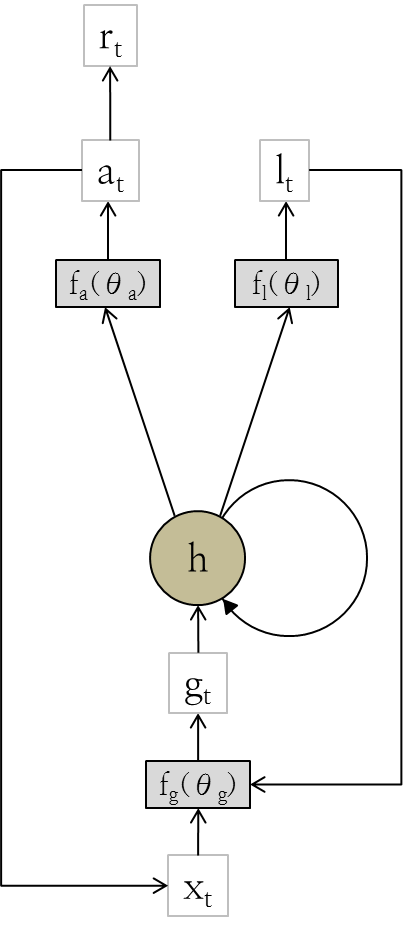
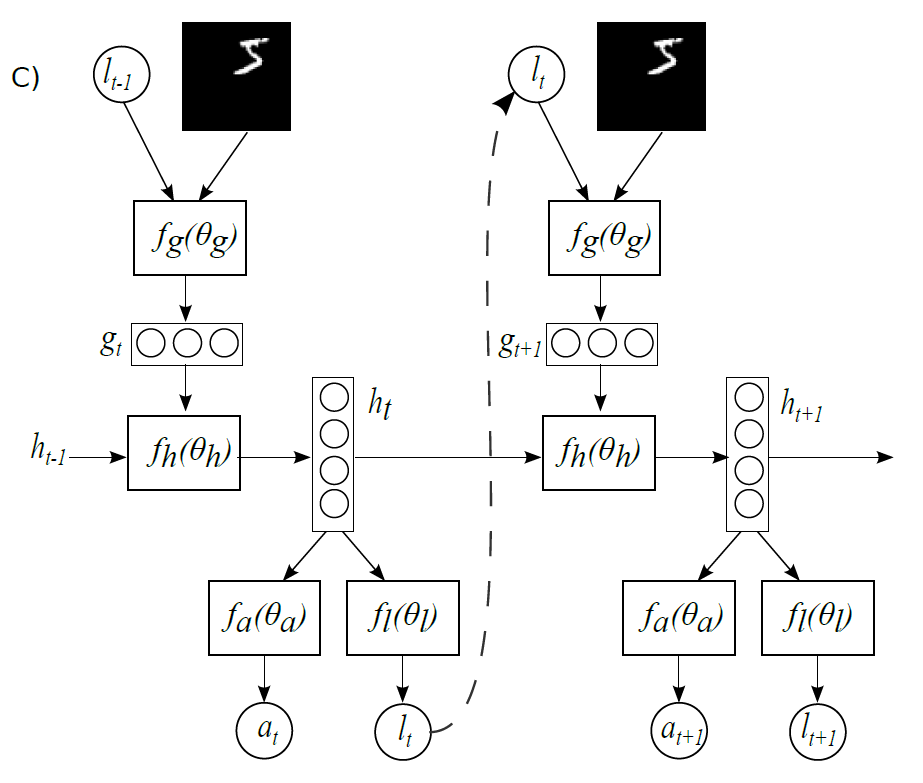
Agent에게는 매 시간마다 전체 image의 일부분 정보인 $x_t$와 바로 전 state를 표현하는 $h_{t-1}$이 input으로 들어온다. 이 정보들을 사용하여 agent는 sensor를 어떻게 움직일 것인지 결정하는 (다음으로 살펴볼 위치 정보를 결정하는) $\ell_t$와 주어진 task를 수행하는 action (이 경우는 image classification이므로 $a_t$ 그 자체가 label 정보를 담은 action이 된다) $a_t$라는 action을 취하게 된다. 이 모델을 시간에 대해 unfold한 것이 논문에 나와있는 Figure 1.c이다.
이때 $f_g, f_\ell, f_a$는 각각 input data에 대한 정보를 처리하는 네트워크 (glimpse network $f_g$), 위치 정보를 결정하는 네트워크 (location network $f_\ell$), 그리고 action의 값을 결정하는 네트워크를 (action network $f_a$) 의미한다. 각각의 네트워크에 대해 하나하나 살펴보도록 하자.
먼저 gimpse network $f_g$는 주어진 input image $x_t$와, 그 중 일부의 위치정보 $\ell_t$ 만을 받아서 원래 image의 일부분만 ‘attention’ 하여 적절한 feature를 뽑아내는 네트워크이다. Glimpse라는 말은 한국어로 ‘언뜻 보다’ 라는 의미를 가지고 있는데, 다시 말해 주어진 이미지를 살짝 훑어보고 그 정보를 잘 정리하여 주어진 RNN core network가 정보를 잘 처리할 수 있도록 만들어주는 역할을 한다. 이 네트워크는 아래 그림과 같이 구성되어있다.
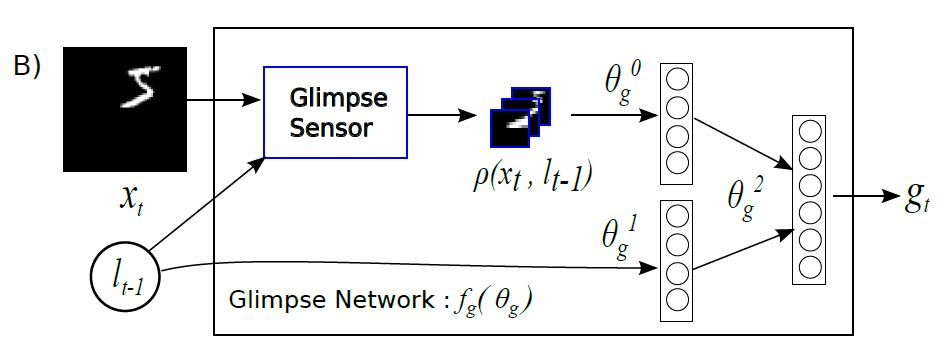
이 네트워크는 glimpse sensor라는 것의 output과 $\ell_{t-1}$의 정보를 concate하는 역할을 한다. 여기에서 중요한 것은 glimpse sensor라는 것인데, 이 센서는 마치 사람의 ‘망막처럼’ (retina-like) 정보를 처리하는 역할을 한다. 즉, 이 센서를 사용해 전체 이미지에서 좁은 영역에 해당하는 정보를 뽑아내는 역할을 하는 것이다. 이 센서는 아래와 같은 구조를 띄고 있다.
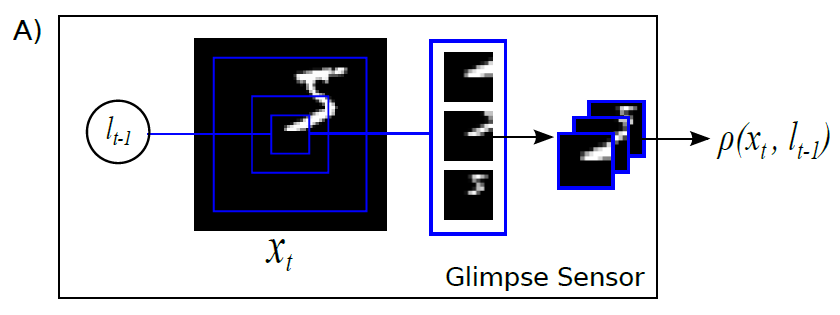
Glimpse sensor는 주어진 이미지 $x_t$의 한 위치 $\ell_{t-1}$을 받아서 해당 위치에서 특정 거리 $d_1$만큼 떨어진 이미지를 추출한다. 그리고 나서 그것보다 더 넓은 범위인 $d_2$만큼 떨어진 이미지를 추출하고, 다시 그것보다 큰 $d_3$만큼 떨어진 이미지를 추출하는 과정을 $k$번 반복하여 $k$개의 patch를 만든다. 이렇게 하는 이유는 사람의 망막이 중심부에 가까울수록 데이터의 해상도를 높게 받아들이고 중심부에서 멀어질수록 이미지가 흐려지도록 처리하기 때문이다. Sensor에서 이 값들을 생성하고 나면 $\rho(x_t, \ell_{t-1})$ 이라는 transform을 처리하게 되는데, image classification 실험을 위해서 사용한 transform은 모든 사진을 같은 크기로 resize한 다음 concate하는 transform이라고 한다. 이렇게 될 경우 중심부에 가까울수록 정보량이 많아지고 정확해지지만 멀어질수록 해상도가 낮은 정보를 받게 될 것이다.
모든 glimpse network의 lyaer들은 기본적인 inner product layer를 사용한다 ($Linear(x) = Wx + b$). 그리고 neuron으로는 ReLU unit ($ReLU(x) = \max(x,0))$을 사용한다. 즉,
$$h_g = ReLU(Linear(\rho(x,\ell))), h_\ell = ReLU(Linear(\ell)) $$
그리고 glimpse network의 output $g$는 $g = ReLU(Linear(h_g) + Linear(h_\ell)$로 정의한다. Glimpse network 말고도 location network와 core network도 거의 같은 방식으로 정의하게 되는데, 각각 $f_\ell (h) = Linear(h)$, $h_t = f_h(h_{t-1}) = ReLU(Linear(h_{t-1}) + Linear(g_t) )$로 정의한다. 이때, core network는 state vecotr $h$의 dimension이 256인 LSTM을 사용한다. 마지막으로 action network $f_a (h) = exp(Linear(h))/Z$, 즉 linear softmax classifier로 정의한다. 그 이외 설정은 모두 앞에서 설명한 것과 같다.
Training
실험에 대해 알아보기 전에, 이 network를 어떻게 learning할 수 있는지 잠시 살펴보도록하자. 이 네트워크에서 우리가 learning해야할 parameter는 glimpse network, core network 그리 action network의 parameter인 $\theta_g, \theta_h, \theta_a$이다. Optimization을 하기 위한 target function은 total reward를 maximize하는 함수로 설정할 것이다. 조금 더 formal한 설명을 위하여 interaction sequences $s_{1:N}$과, 그것의 모든 가능한 state들의 distribution $p(s_{1:T}; \theta)$을 introduce해보자. 이렇게 정의할 경우 우리는 아래와 같은 target function의 $p(s_{1:T}; \theta)$에 대한 expectation을 maximize하는 문제로 reward maximization problem을 formal하게 정의할 수 있다.
$$J(\theta) = \mathbb E_{p(s_{1:T};\theta)} \bigg[ \sum_{t=1}^T r_t \bigg] = \mathbb E_{p(s_{1:T};\theta)} \big[R\big]. $$
그러나 이 함수 $J(\theta)$를 maximize하는 것은 trivial한 일이 아닌데, 다행스럽게도 이미 예전에 다른 work에서 이 $J(\theta)$의 gradient의 sample approximation이 아래와 같이 유도된다는 것을 보였다고 한다.
$$\nabla J(\theta) = \sum_{t=1}^T \mathbb E_{p(s_{1:T};\theta)} \big[ \nabla_\theta \log \phi (u_t ~|~ s_{1:t};\theta) R \big] \simeq \frac{1}{M} \sum_{i=1}^M \sum_{t=1}^T \nabla_\theta \log \phi (u_t^i ~|~ s_{1:t}^i;\theta) R^i . $$
위의 관계식에서의 $\nabla_\theta \log \phi (u_t^i ~|~ s_{1:t}^i;\theta)$은 RNN의 gradient를 계산해야하는 것으로 간단하게 구할 수 있다. 다만 이 관계식이 unbiased estimation of gradient를 제공하기는 하지만, variance가 너무 높다는 단점이 있다고 한다. 그래서 이 논문에서는 아래와 같은 form으로 gradient를 estimation하여 variance의 값을 줄이도록 하였다고 한다.
$$ \frac{1}{M} \sum_{i=1}^M \sum_{t=1}^T \nabla_\theta \log \phi (u_t^i ~|~ s_{1:t}^i;\theta) (R_t^i - b_t), \mbox{ where } R_t^i = \sum_{t^prime=1}^T r_{t^\prime}^i. $$
Experiments
이 논문에서는 MNIST에 대해 실험을 진행했다. 실험은 우리가 보통 사용하는 centered digit, non-centered digit은 물론이고, cluttered non-centered digit에 대한 실험도 진행했다. 마지막 실험은 MNIST digit에 random하게 8 by 8 subpatch를 더하여 데이터를 조금 더 ‘지저분하게’ 만들어서 실험을 진행했다. 비교군은 MNIST의 state-of-art인 모델들이 아니라, 가장 간단한 2 layer fully connect neural network를 사용하였다. 아마 state-of-art 모델들은 워낙 성능이 뛰어나서 아직 극복이 안되는 모양이다. 실험 결과는 아래와 같다.
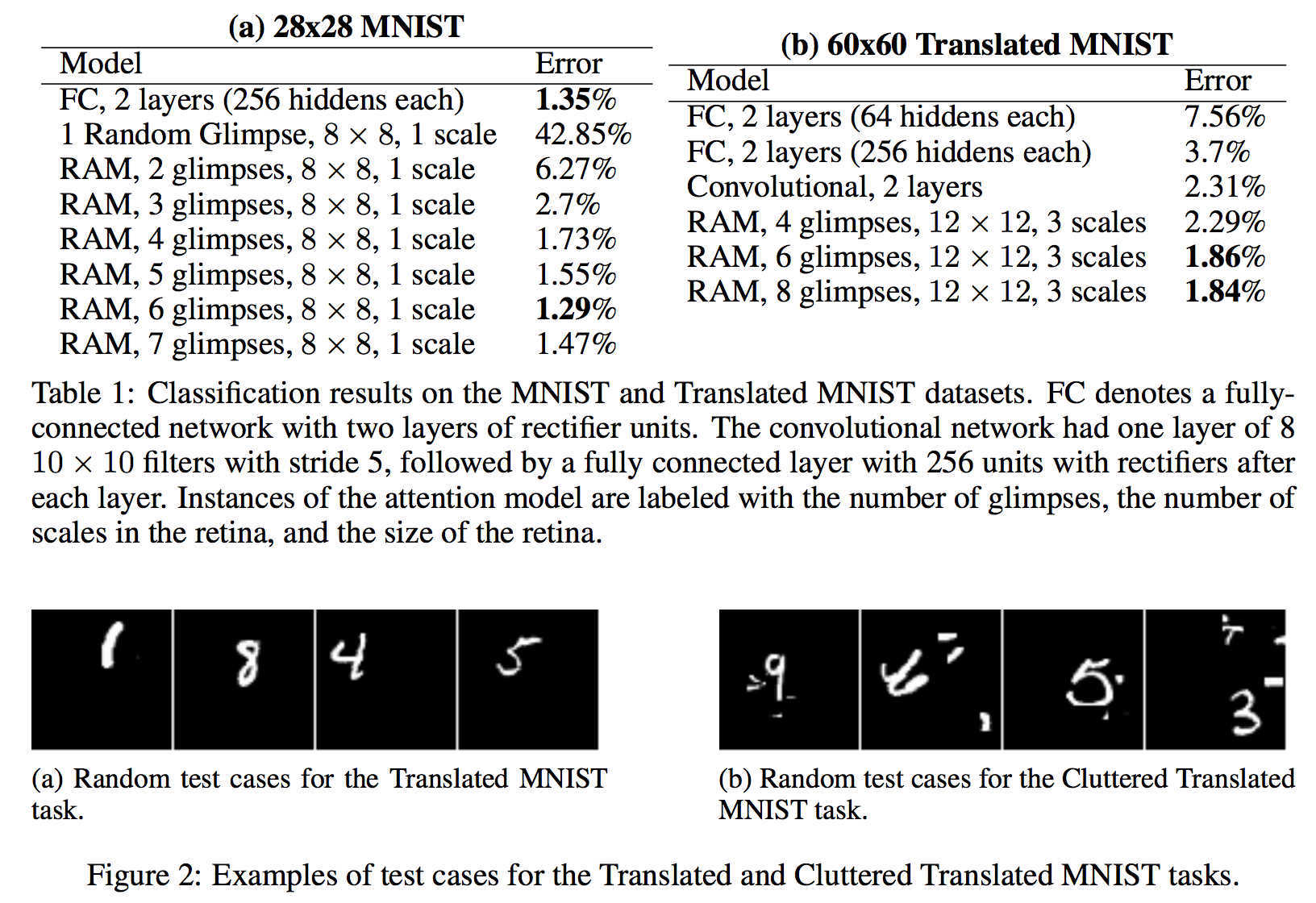
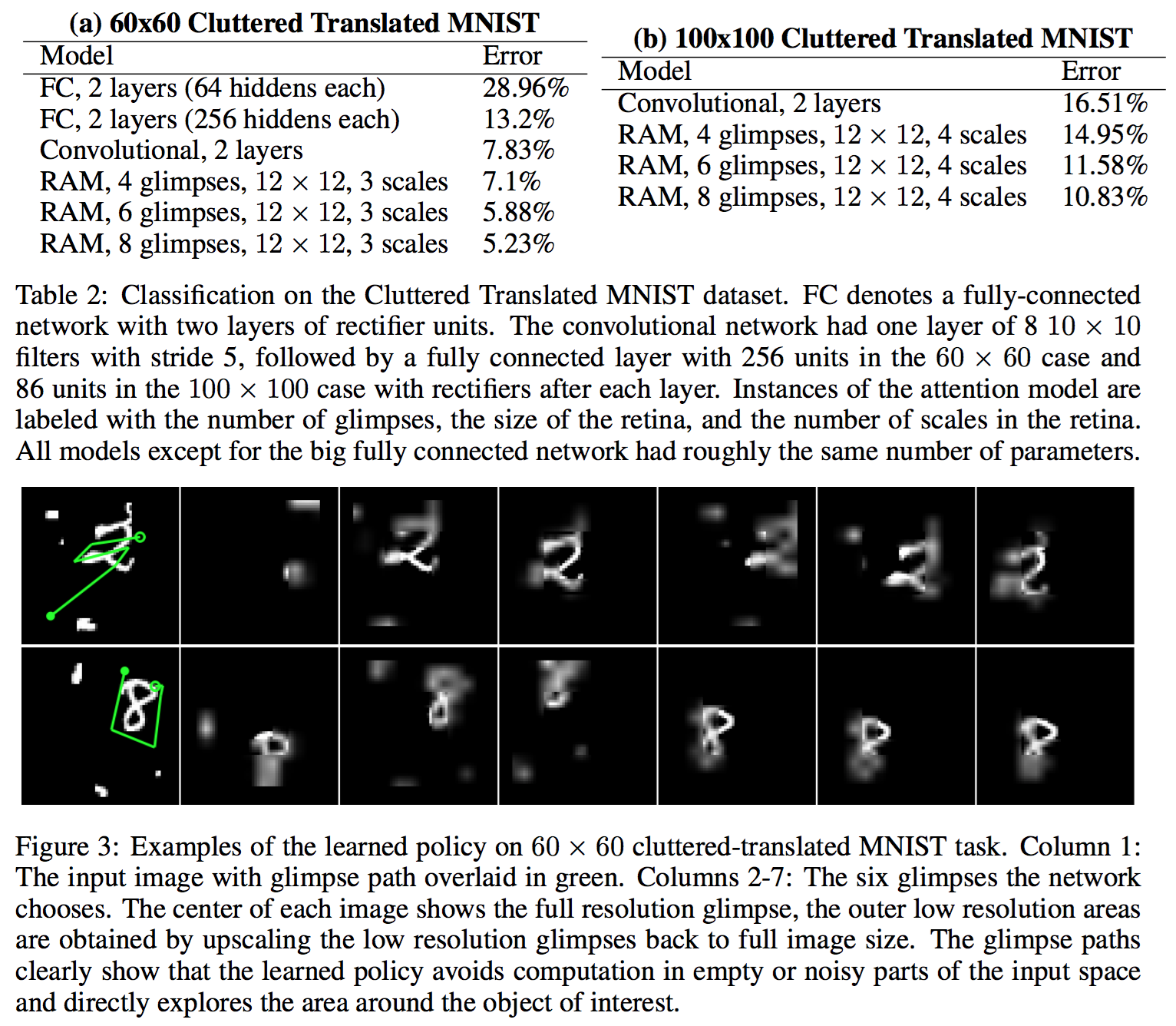
결과가 outperform하다고 할 수는 없지만, 간단한 2-layer fully connected neural network보다 특수한 경우들에 대해 훨씬 잘 동작함을 볼 수 있고, 무엇보다 올바른 classification을 하기위한 policy rule이 (초록색 선으로 표현된 것들) 상당히 human-likely 한 결과를 보인다는 것이 고무적이다. 물론, 이 결과가 GoogleNet이나 AlexNet에 비해 엄청 우수한 결과를 보이느냐하면 그것은 아니지만, 새로운 형태의 접근을 할 수 있다는 가능성을 제시하는 것 만으로도 의미가 있다고 본다. 보다 자세한 실험에 대한 설명은 논문을 참고하면 좋을 것 같다.
Summary of Visual Attention
- 기존 CNN 기반 접근 방식의 문제점들 - 이미지 사이즈에 linear한 computation cost, human-like 하지 않은 처리 방법 등 - 을 처리하기 위한 목적으로 디자인되었음
- 사람이 정보를 한 번에 처리하는 것이 아니라 배경을 무시하고 이미지의 일부만 인식하듯, ‘attention’을 모델에 대입하는 아이디어를 제안함
- Attention을 neural network에 도입하기 위하여 RNN과 Reinforcement Learning을 결합한 형태의 모델을 사용함
- RNN의 input으로는 이미지 정보, 위치 정보가 있으며, 그것들을 조금 더 retina-like하게 처리하기 위한 glimpse network라는 것을 추가로 붙여서 input으로 사용함
- output으로는 action network, location network가 있는데, action network는 classification을 위한 linear classifier이고, location network는 다음 state에 영향을 미치는 recurrent하게 다음 input과 함께 glimpse network의 input으로 쓰이는 값임
- reward는 time t에 올바른 classification을 하였는지 아닌지를 판단하여 0-1 으로 reward를 return함
- train을 하기 위하여 reward maximization을 하는데, 직접 gradient를 구하는 것이 non-trivial하여 estimation값을 사용함. 이때 unbaised estimator는 variance가 높아서 low variance estimator를 사용하여 update를 함
- MNIST에 대해 실험을 하였으며, centered digit은 기존 state-of-art에 비해 턱없이 모자라지만, 사람은 구분할 수 있지만 머신은 제대로 판단하지 못하는 cluttered non-centered digit을 기존 fully connected network보다 훨씬 잘 판별하는 것을 알 수 있었음