들어가기 전에
약 반 년 전에 Coursera에서 Andrew Ng 교수의 Machin Learning Class를 수강한 적이 있다. 사실 당시에 이 course를 수강할 때, 이 course는 introduction course로만 듣고, Geoffrey Hinton 교수의 Neural Network 강의를 들을 생각이었는데, 시간에 쫓기다보니 어느새 나는 석사생이 되었고, 아직도 이 강의를 듣지 못한 상태였다. 그러다가 최근 우연하게 이 강의를 다시 들여다 볼 일이 생기게 되었고, 약 2-3주 동안 이 강의를 듣고 요약글을 꾸준하게 올려 볼 생각이다. 예전 글에서 언급했지만, 내가 너무 쉽다고 생각되면 과감하게 중간부터 요약을 관둘 생각이다.
이 글은 Geoffrey Hinton 교수가 2012년 Coursera에서 강의 한 Neural Networks for Machine Learning 첫 주차 강의를 요약한 글이다. 첫 주차이기 때문에 아주 간단한 introduction course이며, 주로 machine learning과 neural network는 무엇인지 아주 간략하게 설명하는 내용이 주가 된다.
Why do we need machine learning?
사실 이 질문은 물론이고, machine learning이란 무엇인지 내가 아주 많은 글에서 다뤘었기에 자세한 언급은 되도록 피하도록 하겠다. 다만 이 lecture에서는 주로 patterns recognition, anomalies recognition, 그리고 prediction 등의 문제에 집중을 하고 있으며, 특히 image를 classification하는 문제에 focus가 되어있다. 이런 문제의 대표적인 예는 MNIST (hand write letter data base), Face recognition 등이 있다. 실제로 내가 예전에 공부했었던 Neural Network의 대부분은 이런 image process에 focus되어있었다.
What are neural network?
그렇다면 neural network란 무엇인가? 이 질문에 대답하기 이전에 먼저 인간의 뇌가 어떻게 동작하는가에 대해 간략하게 알아보자. 인간의 뇌는 아주 많은 neuron(신경)들로 이루어져 있다. 각 neuron들은 synapse라는 통로를 이용하여 information을 전달하게 되는데, 이런 real human neural network 구조를 아주아주 simplify하면, graph의 형태로 표현이 가능해진다! 즉, 각각의 neuron을 graph의 node, 그리고 synapse를 그 node들을 연결하는 edge로 표현하는 것이다. 여기에서 조금 더 real-likely한 modeling을 하기 위해서 두 가지 factor가 추가된다. 하나는 weight이며 또 하나는 bias이다. 먼저 weight에 대해서 설명을 해보자. 실제 neural network 사이에서 information은 ion이 pumping이 되거나 하는 방식으로 이동하게 된다. 그런데 이 information이 모든 상황에 똑같이 전달되는 것이 아니라, 적절한 학습을 통해서 그 양이 조절이 된다. 즉, 우리가 ‘컴퓨터’라는 물체가 무엇인지 인지하는 과정에서 우리의 뇌로 들어오는 시각정보를 처리하기 위해서 각각의 신경세포들이 서로 다른 양의 information을 전달하게 된다는 것이다. 예를 들어서 우리가 컴퓨터를 봤을 때 모든 시각 정보를 총 동원해서 이것이 컴퓨터다! 라고 판단하는 것이 아니라 일부 특정한 feature들 (예를 들어서 모니터와 키보드 마우스가 있는 모습)을 보고 내가 지금 보고 있는 것이 컴퓨터라는 결론을 내리 듯, 우리의 neural network는 자연스럽게 synatic weight를 학습함으로써 더 정확하고 빠른 연산 및 분류가 가능하도록 설계가 되어있는 것이다. 이런 synaptic weight는 우리가 ‘학습’이라고 부른 과정 동안 계속 update가 된다. 그리고 또 하나 bias에 대해 생각해보자. 만약 우리가 데이터 센터에서 근무를 한다면 아마도 상당히 많은 컴퓨터를 보게 될 것이며, 아마도 대충 네모네모하게 생긴 물건들은 컴퓨터일 가능성이 높지 않을까? 반면 내가 지금 등산 중이라면 아마도 내가 본 물체가 컴퓨터일 가능성은 극히 낮을 것이다. 즉, ‘input이 어떤 특정 결과에 가까울 것이다’를 indicate하는 factor일 뿐 아니라, 그 정도를 조절하기 위한 값이라고 할 수 있는 것이다. 그렇다면 이런 구조의 장점은 무엇일까? 사람의 뇌에는 자그마치 $10^{11}$개의 neuron이 존재한다고 한다. 또한 그 neuron들을 연결하는 link는 약 $10^{14}$개가 존재하게 된다. 그야말로 어마어마한 숫자의 신경들이 비록 하나의 computation power는 떨어질지 몰라도 이것들이 하나의 network를 형성하면서 엄청나게 빠른 parellel computation이 가능해지고 엄청나게 빠른 연산이 가능해지는 것이다. 거기에 각 neuron들이 information을 저장하고 있기 때문에 단순히 RAM으로 binary bit를 저장하는 것과는 차원이 다른 용량을 저장할 수 있게 되는 것이다.
자 그러면 이제 human neural network가 어떻게 동작하는지 살펴보았다. 그렇다면 이런 뛰어난 model을 어떻게 real field적용할 수 있을까? 우리의 뇌가 그야말로 컴퓨터에 비해 outperformance를 보이는 분야에 이런 아이디어를 적용하면 좀 그 성능이 개선되지 않을까? 그야말로 많은 사람들이 얘기하듯 컴퓨터는 멍청하다. 인간이 만든 system에 정해진 input이 들어는 상황에서는 무엇보다 빠르고 정확한 computation을 보여주지만, 스스로 무언가를 ‘판단’할 수 없으며, 사람에 비해서 그 유연성이 매우 떨어진다. 때문에 AI를 연구하는 사람들에게 스스로 ‘학습’하는 machine learning이 새로운 대안으로 제시되고 이 분야가 AI에서부터 시작되었다는 점이 전혀 놀랍지 않은 것이다. 잠시 얘기가 샛길로 빠졌는데, 결국 사람이 컴퓨터에 비해서 엄청 잘 할수 있으며 실제 real field에서 수요가 많은 대표적인 문제가 바로 image processing이다. 컴퓨터는 image를 pixel map으로 밖에 인식할 수가 없다. 즉, 가장 많이 쓰이는 example인 MNIST handwrite database를 보면, 각 이미지는 28 by 28 pixel map이며, 다시 말해서 이미지 하나에 총 784개의 information이 존재한다는 것을 알 수 있다. 이 database는 흑백 사진이니깐 그냥 간단하게 까만 것과 하얀 것으로 구분하면, 총 784개의 binary 값을 component로 가지는 vector로 생각할 수 있을 것이다. 하지만 내가 위에서도 잠깐 언급했던 것 처럼 우리는 절대로 그 시각정보를 전부 활용하여 물체를 인지하지 않는다. 일부 ‘feature’를 인식해서 내가 지금 보고 있는 것이 무엇인지 판단하게 되는데, 안타깝게도 컴퓨터는 그런 작업이 불가능한 것이다.
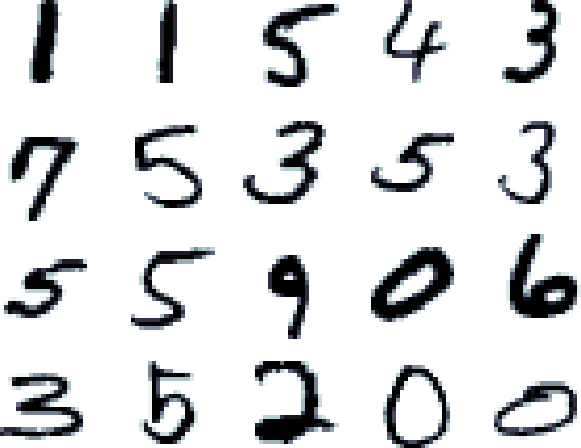
위의 사진이 바로 MNIST dataset의 일부분인데, 우리는 바로 각 글씨가 무엇을 의미하는지 바로 인지할 수 있지만, 멍청한 컴퓨터는 이 글씨들을 10개의 digit으로 바로 인지하는 것이 아니라 784 차원의 vector로 인식하게 되는 것이다. 앗 잠깐, 그런데 우리가 ‘바로’ 인지하는 것도 사실 뇌가 연산을 한 결과가 아닌가? 그렇다면 뇌가 어떻게 동작하는지를 ‘모방’하면 기존의 방법들보다 더 나은 새로운 방법이 나올 수 있지 않을까? 그렇다! 이것이 바로 artifitial neural network의 motivation이다. 인간의 뇌는 엄청나게 빠르고 엄청나게 많은 연산을 자그마치 ‘parellel’하게 처리한다! 이는 정말 optimal한 system이 아닐 수 없다. 때문에 neural network의 application의 대다수는 이런 vision 문제를 해결하기 위해 사용이 된다.
Some simple models of neurons
이제 neural network의 필요성과 기본적인 구조는 알았으니, 구체적으로 우리가 그것을 구현하기 위한 모델을 만들어보자. 앞서 얘기했듯 우리의 artifitial neural network는 input이 들어오고, 각 graph의 weight와 맨 처음 설정한 bias를 통해 output을 얻어내는 구조이다. 즉, input을 x, weight를 w, bias를 b, output을 y라고 한다면,
$$ y = b + \sum_i x_i w_i $$
와 같은 식을 얻을 수 있을 것이다. 여기에서 $x_i$는 i번 째 input을 의미한다. 즉, MNIST에서 24 by 24, 784개의 input들에 대해서 모든 component들 (각 pixel들)의 값에 weight를 곱하고 그걸 모두 더한 다음 bias를 더해준 결과가 output인 것이다. 매우 간단한 시스템이다. 그렇다면 소제목인 ‘Some simple models of neurons’은 무슨 의미란 말인가?? 별건 아니고, output을 바로 사용할 것이냐 아니면 무언가 다른 형태로 modeling하여 사용할 것이냐에 대한 문제이다. 앞서 설명한 수식은 neuron들을 계산한 결과가 바로 최종 output이 된다. 그러나 실제로는 이것 말고도 많은 모델들이 존재하는데, 예를 들어서 $z = b + \sum_i x_i w_i$ 라고 했을 때 y의 값을 z가 0보다 크면 z값을 그대로 사용하고 0보다 작으면 0이라고 할 수도 있을 것이다. 이런 모델을 Rectified Linear Neurons이라고 하며 linear threshold neuron이라고 하기도 한다. 또한 0보다 작으면 0, 0보다 크면 1이 되도록 하는 binary threshold neuron도 생각할 수 있다. 실제로 우리가 사용하게 될 model은 바로 sigmoid neuron이다. Sigmoid function은 매우 간단한데, 다음과 같은 모양이다. $y = \frac 1 {1+e^{-z}}$ 이런 형태가 되면, z가 양의 방향으로 무한하게 커진다면 아래 항이 1이 되므로 값이 1이 되고, z가 무한하게 음의 방향으로 커진다면 아래 항이 무한하게 발산하게 되어 전체 식의 값이 0이 되는 것이다. 즉, 아래와 같은 모양을 띄게 되는 것이다.
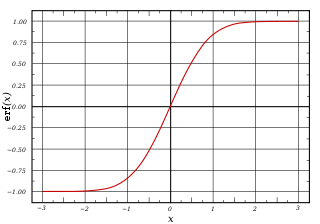
대부분의 경우 우리가 필요한 output은 binary이므로 (0또는 1이므로) 이 함수의 결과가 output의 확률을 나타내는 stochastic binary neuron을 생각하는 것이 가능하다. 즉, $p(y=1) = \frac 1 {1+e^{-z}}$ 로 표현하고 output의 값을 stochastic하게 예측하는 방법을 사용할 수 있는 것이다. 아마 앞으로 neural network라 하면 이런 stochastic model이 중심이 된다고 생각하면 될 것이다.
A simple example of learning
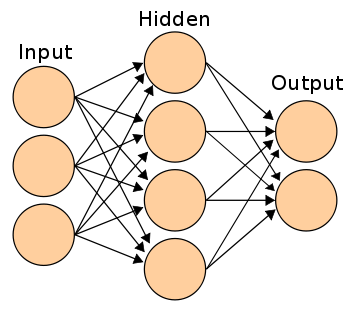
이 부분은 사실 크게 설명할 것은 많이 없고, 그렇다면 이런 neural network를 실제 이미지 recognition에 어떻게 사용할 것이냐.. 에 대한 부분이다. MNIST를 예로 들면 임의의 784 pixel map이 들어왔을 때 10개의 class (0~9) 중에서 어느 class에 해당하는지 어떻게 예측할 것이고 어떻게 decision을 내릴 것인가! 에 대한 실제 예시를 다루는 것이다. 이미 class가 정해진 이미지들을 가지고 neural network의 weight들을 학습하고, 그 결과를 통해 class를 구분하는 것이다. 한 가지 방법은, neural network를 layer처럼 쌓는다고 생각했을 때 (아래의 첫 번째 그림) 만약 이 network에서 맨 마지막 layer에서 어떤 특정한 shape으로 수렴하도록 만들었을 때 그 수렴한 결과를 이용해 class를 구분할 수 있을 것이다 (마찬가지 아래 두 번째 그림).
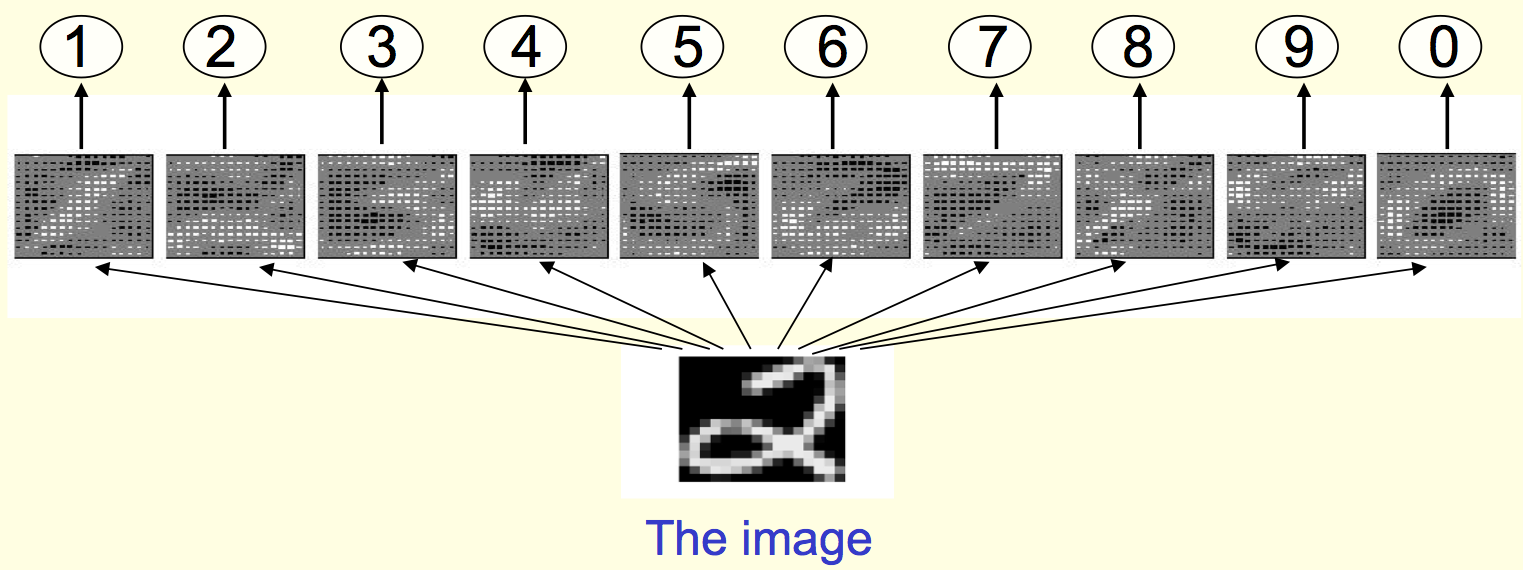
이렇게 복잡하게 해야하는 이유는 몇 개의 간단한 알고리듬, 예를 들어서 아래 삐침 글자가 오른쪽으로 뻗으면 ‘2’ 라고 하는 등의 간단한 rule을 각각의 class에 대해 만들어서 이 rule에 의해 determistic하게 결정하는 무지무지 간단한 heuristic algorithm이 아니라 neural network을 쓰는 이유는, 실제 우리가 생각할 수 있는 것보다 엄청나게 많은 variation이 존재하고 (심지어 숫자임에도 불구하고!) 이 때문에 이런 heuristic한 방법으로는 좋은 performance가 나오기 힘들기 때문이다. 특히 MNIST에는 갈겨 쓴 글씨가 많아서 더 그럴지도..
Three types of learning
machine learnig에는 supervised learning, reinforcement learning, unsupervised learning 총 세 가지 큰 범주가 존재한다. 각각에 대한 설명은.. 워낙 많이 했기에 생략하고 (reinforcement learning은 한 적은 없지만, neural network의 main interest가 아니다) 간단하게 설명하면, neural network로 supervised learning을 하는 것이 앞의 절반, 그리고 unsupervised learning을 하는 것이 뒤의 절반이 될 예정이다. 특히 엄청나게 오래되고 old한 neural network가 재조명을 받고 연구가 활발하게 된 가장 큰 이유가 Deep learning 등의 unsupervised learning임을 감안해봤을 때, 매우 기대가 되는 부분이다. (대부분의 교재는 supervised learning에 대해서만 다룬다.)
Conclusion
이 렉쳐는 워낙 intro level이고.. 예전에 중복해서 다룬 개념이 너무 많아서 생략한 내용이 좀 많다. 최대한 자세하게 적으려 노력했지만, 의아한 부분이 있으면 위키피디아 등에 자세히 설명이 되어있으니 그 글들을 참고해주길 바란다.
Coursera Neural Networks for Machine Learning
다른 요약글들 보기 (카테고리로 이동)
- Lecture 1: Introduction
- Lecture 2: The Perceptron learning procedure
- Lecture 3: The backpropagation learning proccedure
- Lecture 4: Learning feature vectors for words
- Lecture 5: Object recognition with neural nets
- Lecture 6: Optimization: How to make the learning go faster
- Lecture 7: Recurrent neural networks
- Lecture 8: More recurrent neural networks
- Lecture 9: Ways to make neural networks generalize better
- Lecture 10: Combining multiple neural networks to improve generalization
- Lecture 11: Hopfield nets and Boltzmann machines
- Lecture 12: Restricted Boltzmann machines (RBMs)
- Lecture 13: Stacking RBMs to make Deep Belief Nets
- Lecture 14: Deep neural nets with generative pre-training
- Lecture 15: Modeling hierarchical structure with neural nets
- Lecture 16: Recent applications of deep neural nets