들어가기 전에
이 포스트는 2014년 6월 16일 카이스트에서 당시 Yoshua Bengio 교수님 연구실에서 포닥 과정을 밟고 계신 조경현 박사님의 The Basic Principles in Deep Neural Networks 라는 이름의 세미나를 요약한 내용이다. 내용은 주로 Deep learnining을 supervised learning, unsupervised learning의 관점에서 각각 바라보면서 어떤 컨셉들이고, 어떤 연구들이 진행이 되어있는지 훑어보는 정도의 간단한 내용이었다.
어쩌다보니 1년 넘게 포스팅을 못하다가 이제와서 포스트를 등록하게 되었는데, 이 글을 제대로 정리할 정도로 여유가 없기도 했고, 내가 이 내용을 이해할 수 있을 정도의 내공이 없기 때문이기도 했다. 지금은 어느 정도 여유가 생기기도 했고, 내가 내용을 대략이나마 이해하고 있기 때문에 일 년 전 내용이기는 하지만, 다시 한 번 내용을 정리해서 올려본다.
이 세미나는 크게 네 가지 파트로 나뉘어진다. 먼저 Deep learning이 무엇인지 간단한 introduction part, supervised deep learning, unsupervised deep learning, 마지막으로 아직 연구가 진행 중인 advanced topic이다. 이 글에서는 introduction과 supervised learning part에 대해서 주로 다루고, 나머지 부분에 대해서는 간단하게 훑고 지나가기만 하도록 하겠다.
Part 1 - Introduction
Deep Learning이 무엇인지 알기 전에 먼저 Machine Learning이 무엇인지 알 필요가 있다. Machine Learning에 대해 보다 깊게 알고 싶다면 내가 아직 계속 작성 중인 Machine Learning Study 글들을 읽어보아도 좋고, 다른 좋은 글들을 참고해도 좋을 것 같다. 이 세미나에서는 Machine Learning이 주 주제가 아니기 때문에, 머신러닝이라는 것을 ‘데이터를 통해 모델을 learning하고 learning한 모델을 사용해 주어진 query에 대답하는 것’이라고 정의하였다. 결국 내가 예전 글에서 아래 그림에서 정의했던 것과 크게 차이는 없다.
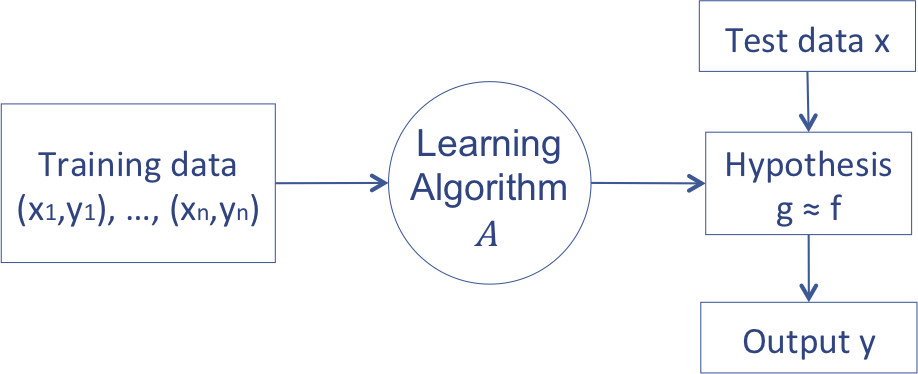
Deep Learning에 대해 설명하기 전에 먼저 perception이라는 문제에 대해 살펴보자. Perception이란 우리말로 하면 ‘인지’ 정도로 해석할 수 있다. 이 문제는 주어진 정보에 대해 내가 필요한 어떤 특정 정보를 inference 하는 것이다. 예를 들어서 이 포스트의 글자가 무엇인지 읽어들이는 문제는 간단한 문제이지만, 이 문장들을 바탕으로 어떤 의미를 가지고 있는지 inference하는 것은 어려운 문제이다. 또 다른 예로는 vision 데이터를 하나 주고 주어진 vision data가 어떤 object인지 classification하는 문제도 perceptron이다. 이 문제는 사람에게는 아주 간단한 문제이지만 컴퓨터에게는 엄청나게 어려운 문제이다. Deep learning은 사람이 perception하는 방식을 모방하여, 사람만큼 perception을 해보자는 취지로 만들어진 model이라고 생각할 수 있다. 사람은 뇌의 neuron과 synapse 등으로 대표되는 일어나는 일렬의 화학적, 전기적 신호 전달 과정을 통해 perception을 하게 된다. 이것을 수학적 모델로 표현하고, 그것을 조금 deep하게 만든 것이 deep learning이다. (Neural Network와 이에 대한 intuition을 조금 더 자세히 알고 싶다면 내가 쓴 Neural Network Introduction과, Deep Learning 1을 읽어보기를 권한다.)
Deep Learning이라는 분야는 최근 10년 동안 엄청나게 hot해진 분야이다. 그런데 사실 deep learning이라는 분야, 혹은 neural network는 사실 4-50년도 넘은 엄청 오래된 분야이다.
- 1958 Rosenblatt proposed perceptrons
- 1980 Neocognitron (Fukushima, 1980)
- 1982 Hopfield network, SOM (Kohonen, 1982), Neural PCA (Oja, 1982)
- 1985 Boltzmann machines (Ackley et al., 1985)
- 1986 Multilayer perceptrons and backpropagation (Rumelhart et al., 1986) 1988 RBF networks (Broomhead&Lowe, 1988)
- 1989 Autoencoders (Baldi&Hornik, 1989), Convolutional network (LeCun, 1989) 1992 Sigmoid belief network (Neal, 1992)
- 1993 Sparse coding (Field, 1993)
즉 우리가 지금 쓰고 있는 Neural network의 기본적인 연구는 이미 90년대 이전에 다 끝나있었다. (심지어 1995년에 Machine Learning에 어마어마한 연구 결과를 남긴 Vapnik과 Jackel이 10년 뒤인 2005년에 아무도 Neural net을 쓰고 있지 않을 것이라고 내기를 했을 정도라고 한다) 근데 갑자기 Deep learning이 왜 이렇게 hot해졌을까? 이는 내가 Machine Learning 스터디 (19) Deep Learning - RBM, DBN, CNN 글에서 자세히 다뤘으므로 이 글에서는 간단하게 결론만 말하도록 하겠다. 그 이유는 Deep Learning이 ImageNet에서 기존 결과를 거의 박살을 냈기 때문이다. Deep Learning이 나오기 전에는 error가 0.27 ~ 0.30정도, 그러니까 27%에서 30% 정도였다고 한다. 기존 computer vision 연구자들은 이 정도 결과가 거의 한계치라고 여겨지고 있었는데 갑자기 2012년에 Deep convolutional neural network를 하는 팀이 0.153으로 거의 2배 가까운 성능 향상을 보여주었다고 한다. 그리고 그 다음 해에는 상위 20개 팀에서 2개 팀 빼고 전부 Deep learning을 써서 Classification을 했는데, 최고 성능은 또 0.117로 개선되었다고 한다. 그 결과 computer vision을 비롯한 기존 학계에서 엄청나게 주목을 받게 되었다고 한다.
Deep learning에 주목하는 것은 학계만이 아니다. Deep learning을 기본 기술로 사용하는 스타트업도 엄청나게 늘어나고 있고, (Deep learning 기술 회사인 Deep mind M 이상에 인수, Captcha 퍼즐 암호 99.8% 성공률로 해석, 사람의 얼굴 인식 능력을 상회하는 소프트웨어 개발) 심지어 현재 구글이나 애플 등에서 음성 인식에 쓰는 알고리듬도 deep learning이다. 이렇듯 deep learning은 학계에서만 관심을 가지는 분야가 아니라 실제 산업에서도 아주 빠르게 적용되고 사용되고 있는 분야이기 때문에 더더욱 주목할만하다. 보통 학계에서 연구한 결과가 실제 산업에서 적용되기까지의 시간이 분야마다 조금씩 다른데, deep learning은 오히려 산업에서 먼저 개발하고 학계에 발표할 정도로 학계와 산업이 함께 집중하고 있는 분야이다.
What is ‘Deep’ Learning?
기존 machine learning 문제를 푸는 방법은 크게 3단계로 구분 할 수 있다.
- Feature Engineering: 주어진 데이터를 사용해 machine learning tool에서 사용할 수 있는 feature를 뽑아내는 과정. 이 과정은 machine learning이 아니며, domain knowledge와 engineer의 knowhow가 강하게 drive하는 과정
- Learning: 1에서 주어진 feature 데이터를 사용해 machine learning model을 train하는 과정
- Inference: 2에서 학습한 model을 사용해 새로운 데이터를 inference하는 과정
첫 번째 단계는 machine learning은 아니지만, 실제 최종 performance에 큰 영향을 미치는 과정이다. 예를 들어 우리가 SVM을 사용해 image를 학습한다고 가정해보자. 100만 화소짜리 이미지를 사용해 learning을 해야하는 경우, 1번 과정이 없으면 우리는 엄청나게 high dimensional data를 사용해 SVM을 풀어야하지만, 이렇게 높은 dimension의 데이터를 사용하게 되면 curse of dimensionality 등의 문제로 인해 나쁜 performance를 얻게 될 확률이 크다. 그 밖에도 특정 pattern의 noise가 계속 등장하고 그 noise로 인해 outlier가 많이 생기는 등의 상황도 생길 수 있다. 특히 여러 multi media 데이터를 처리하기 위해서는 이 feature engineering이 중요한 문제이며, 단순히 feature를 잘 고르는 것 만으로도 어려운 모델을 사용하지 않고 가장 간단한 linear 모델만으로도 문제가 해결되는 경우도 많이 있다 (예: 지문 인식). 때문에 이 과정은 절대 무시할 수 없는 과정이지만 domain knowledge에 너무 크게 dependency가 있고, general purpose machine learning과 분리가 된다는 문제가 존재한다. 그러나 여기에서 중요한 점은, domain knowledge를 반영하는 것이 그렇지 않은 것에 비해 훨씬 더 우수한 결과를 낸다는 점이다.
그렇기 때문에 우리는 feature 역시 machine learning technique를 사용해 learning해보자는 idea를 제안할 수 있다. 예를 들어 앞에서 제안한 image같은 경우, PCA 등의 dimensionality reduction technique들을 사용한다면 더 낮은 차원의 데이터로 문제를 해결할 수 있다.
1-a. Feature Engineering: domain knowledge를 반영하여 representation learning의 input으로 사용할 feature를 생성하는 과정 1-b. Feature/Representation Learning: 1-a의 결과를 사용해 PCA 등의 unsupervised feature learning을 뽑아내는 과정 2. Learning: 생략 3. Inference: 생략
이 경우 feature extraction에서도 general machine learning 방법론을 적용할 수 있다는 장점이 존재하지만, 여전히 representation learning은 domain knowledge를 반영하지 못하기 때문에 domain knowledge와 general machine learning 간의 간극이 발생한다. 다시 말해서, PCA는 Image data의 특성을 살릴 수 없는 learning 모델이기 때문에, 결국 domain knowledge를 반영하기 위한 새로운 feature engineering 과정이 필요하다는 의미이다.
Deep learning은 이런 문제를 해결하기 위하여 아래와 같은 모델을 제안한다.
- Jointly learning everything: 한 번에 모델 하나로 feature engineering, representation learning, model learning까지 끝내는 과정
- Inference
우리가 domain knowledge를 반영하여 모델을 하나 설계한 다음, 나머지 feature engineering이나 representation learning 등의 과정을 한 번에 짬뽕해서 해결하자는 것이다. 이것이 가능한 이유는 deep learning 모델의 특성 때문이라고 할 수 있다. Neural network 모델은 아래 그림처럼 layer가 쌓여있는 형태로 구성이 되어있는데, 마치 각각의 layer를 feature extraction 과정으로 바꿔서 생각할 수 있다. 위로 올라갈수록 점점 우수한 feature를 뽑아내게 되고, 맨 마지막 layer에서 linear classifier를 learning하는 과정처럼 생각할 수 있는 것이다.
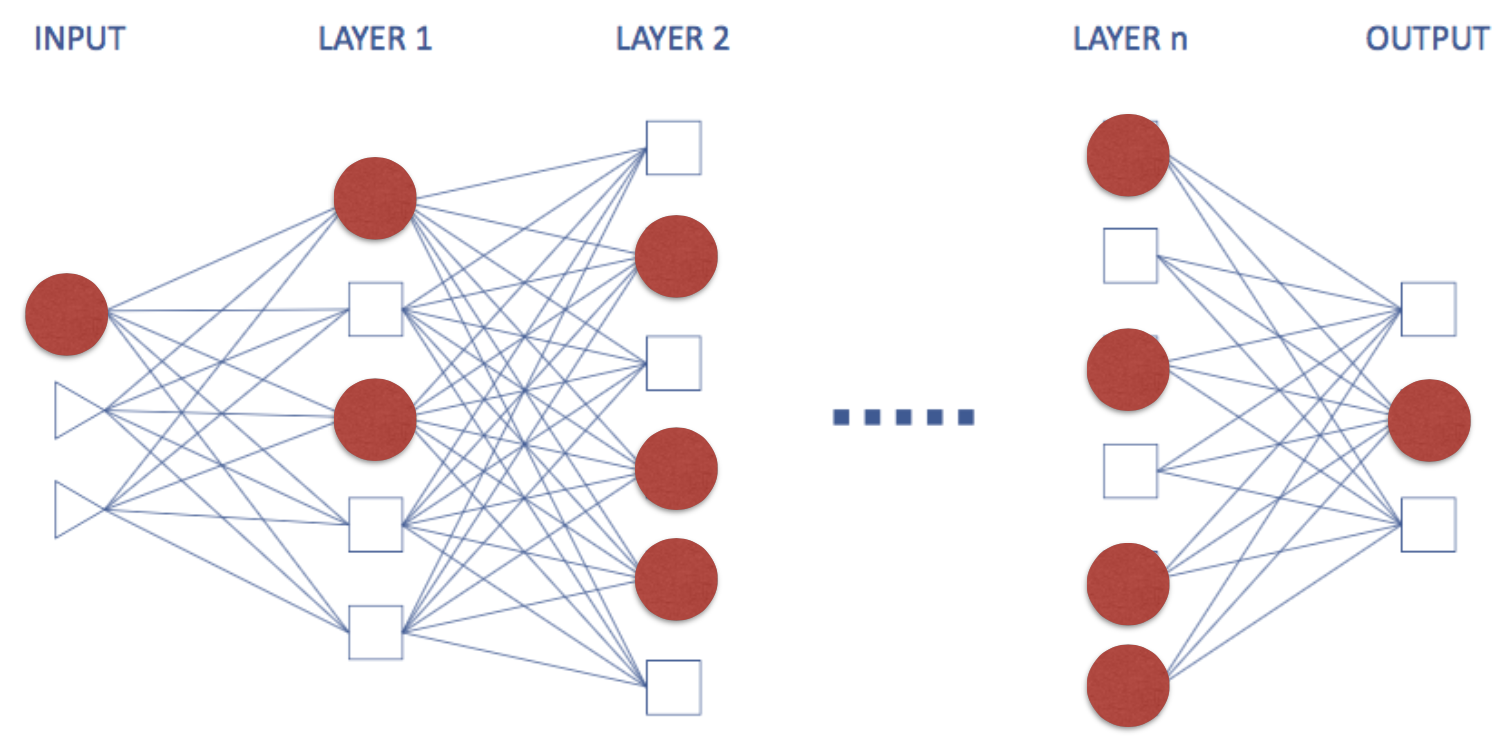
또한 중요한 것은, PCA 등의 unsupervised feature extraction을 결합한 경우에는 feature extraction이 unsupervised learning이기 때문에 데이터나 최종 output loss function에 영향을 받지 못하는데 반해서, deep learning model은 모든 것들을 하나의 loss function으로 한 번에 handle하기 때문에 모든 것들을 jointly learning한다고 표현할 수 있는 것이다. 이를 가장 잘 표현하는 말이 Yoshua Bengio 교수의 “Let the data decides”라고 할 수 있다. 어떤 모델을 써야 좋은 feature를 뽑을 수 있을까에 신경쓰지말고, 처음부터 deep learning 모델처럼 좋은 모델을 사용해 데이터에서부터 좋은 결과를 낼 수 있도록 데이터가 알아서 하도록 하라는 취지의 말인데, 개인적으로 이 얘기는 특히 CNN 모델에 잘 맞는 얘기라고 생각한다. 예전 글에서도 다뤘듯이 CNN은 모델은 vision 데이터의 특성을 최대한 활용하여 feature map을 만들어내는 것이 목적이다보니, convolution과 polling layer는 최대한 feature를 만들어 내는 과정으로 쓰이고, fully connected layer에서 해당 feature를 사용하여 classification을 하는 형태가 된다. 그렇기 때문에 한 번에 preprocessing 혹은 feature engineering part와 learning하는 part가 합쳐진 형태가 되는 것이 아닐까 추측해본다.
그러나 단순히 deep learning을 사용하면 feature extraction과 결합된 형태로 모델을 learning할 수 있다는 이유로 아무도 쓰지 않던 deep learning을 많이 쓰기 시작한 것은 아니다. Deep learning을 많이 연구하게 된 원인으로 박사님은 두 가지 이유를 꼽았는데, 하나는 서로 다른 분야라고 생각하면서 연구되었던 PCA, Neural PCA, Probabilistic PCA, Autoencoder, Belief Network, Restricted Boltzmann Machine 등의 분야가 사실은 서로 각자의 특수한 케이스이거나 혹은 다른 표현형이라는 것이 알려지면서 결국 한 분야로 수렴하였다는 것과, 또 하나는 예전에는 알려지지 않았던 것들이 이제는 많이 알려져서 예전에는 어렵게 접근했던 것들을 이제는 쉽게 learning할 수 있다고 한다. 그 중에서 특히 non-convex optimization에 대해 많은 기술들이 연구되어서 non convex optimization이기 때문에 optimization이 불가능하다고 두려워 할 필요가 없다는 것이 가장 큰 이유라고 한다. 또한 inference와 training사이의 interaction에 대해서도 더 많이 이해하고 있다는 점도 꼽을 수 있으며, GPU 등의 하드웨어 발전으로 인해 예전보다 computation power가 exponential하게 증가한 것도 그 중의 한 원인이라고 한다.
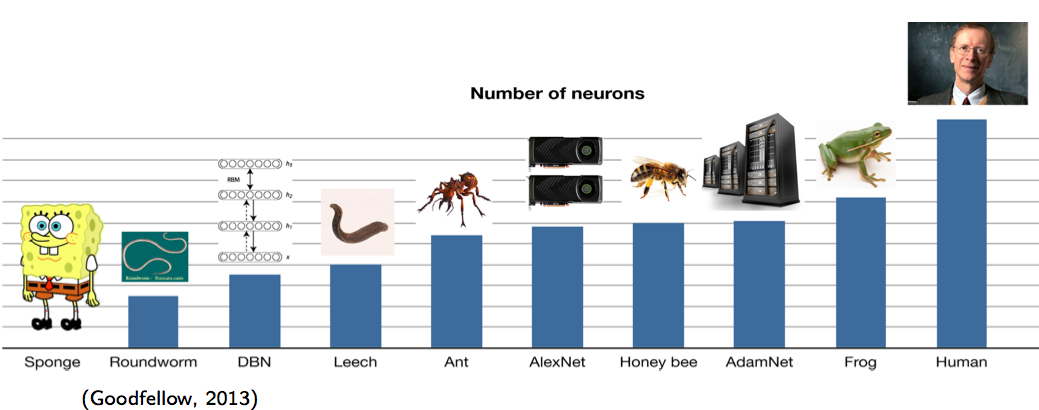
위의 그림은 각 종과 현재 개발된 NN들의 뉴런 개수를 비교한 것이다 (y 축 뉴런 개수의 스케일은 log scale이다). 맨 처음 DBN이 나올 때만 해도 편충보다 뉴런이 조금 많고 거머리보다 10배 적었다. 2012년 ImageNet에서 우수한 성과를 거둔 AlexNet의 neuron 개수는 개미보다 조금 많고 벌에 비해서 한참 적다. 그리고 2014년 기준으로 가장 큰 AdamNet의 뉴런 개수는 아직도 개구리의 뉴런 개수보다 적다. 그렇기 때문에 앞으로 사람이 가지고 있는 뉴런의 개수만큼 뉴런을 가지는 NN 모델이 개발되려면 많은 시간이 남았다고 전망하고 있다. 뉴런의 개수가 많을수록 좋은 모델이 된다는 것은 이미 알고 있지만 뉴런의 개수를 단순하게 많이 늘릴 수 없는 이유는 learning time이 엄청나게 오래걸리기 때문이다. 개인적으로는 이 부분이 아직까지도 deep learning이 발전할 여지가 많이 있다는 것을 의미한다고 생각한다. 왜냐하면 뉴런의 개수를 늘리는 일은 computation cost가 엄청나게 많이 드는 일이고, parameter 역시 exponential하게 증가하기 때문에 overfitting issue를 handle하는 것이 점점 더 중요해지기 때문이다. 더 이상의 regularization은 없다고 생각할 수도 있지만, 최근에 나온 Batch Normalization work이 dropout 등의 기존 성과를 뛰어넘는 좋은 performance를 내고 있는 것을 보면, 충분히 더 좋은 접근 방법이 나올 수 있을 것이라고 믿는다.
Part 2 - Supervised Neural Network
Deep learning도 machine learning의 일종이기 때문에 supervised/unsupervised/reinforcement learning의 세 가지 접근 방법으로 바라보는 것이 가능하다. 이 part에서는 neural network로 supervised learning, 특히 classification을 어떻게 푸는지에 대해서 주로 다뤘었다. 세미나에서는 multilayer perceptron과 그것의 learning, regularization, 그리고 기타 등등에 대해 다뤘었지만, 이 글에서는 learning algorithm인 back-propagation에 대한 설명은 예전에 쓴 글의 링크로 대체하고, 주로 어떻게 MLP를 regularization할 수 있는지 등에 대해서 다룰 것이다.
예전에도 설명했듯 neural network는 back-propagation이라는 알고리즘을 사용해 model parameter를 찾는다. 이 알고리즘은 any cost function이 주어졌을 때, 그 문제를 풀기 위한 gradient descent method를 chain rule을 사용해 간단하게 바꾼 알고리즘이라고 할 수 있다. 이 알고리즘을 사용하게 되면 모든 노드의 derivative를 전부 계산할 필요가 없고, 대신 매우 적은 양의 계산으로 마치 전체의 gradient를 계산한 것과 같은 효과를 얻을 수 있기 때문에 NN update는 거의 이 방법을 사용한다. 또한 모든 data에 대한 gradient를 계산하여 완벽한 gradient를 찾는 대신, batch라는 개념을 도입해 stochastic gradient descent method를 사용해 문제를 해결한다. 원래 문제가 Convex가 아니기 때문에 제대로 된 gradient descent와 SGD가 서로 다른 곳으로 수렴하기는 하지만, 이 점은 크게 중요한 이슈는 아니라고 한다.
여기에서 질문이 하나 나왔었다. 이렇게 할 수 있는 이유는 neural network에서 chain rule을 적용할 수 있기 때문인데 혹시 그렇다뎐 Hessian을 계산할 수는 없을까라는 질문이 나왔다. 왜냐하면 second derivative method가 gradient method보다 훨씬 좋다는 것은 이미 잘 알려진 사실이기에, 만약 Hessian을 efficient하게 계산할 수 있다면 learning 속도를 크게 향상시킬 수 있을 것으로 기대할 수 있기 때문이다. 그러나 아직까지는 실제 NN에서 Hessian 등의 2nd derivative를 계산하는 것은 Hessian Matrix를 계산해야할 뿐 아니라, 그것의 inverse까지 계산해야하므로 매우 expensive하다고 하고, 구현도 복잡하다고 한다. 그렇기 때문에 대신 Hessian matrix를 직접 구하지 않고 그것의 inverse를 estimate하는 방법들이 있지만, 그러나 여전히 큰 NN에는 부적합하기 때문에 보통 Gradient를 사용한다고 한다 (여기에서 언급된 Hessian matrix의 inverse를 estimate하는 방법을 Hessian-Free optimization이라고 부른다).
Regularization
Regularization을 Bayesian 관점에서 바라본다면 좋은 prior를 제안하는 것과 같다. 예를 들어 ‘모델이 이렇게 복잡할리 없으니 모델의 complexity를 penalty term으로 추가해야겠다’ 라는 regularization method도 model complexity에 대한 prior를 반영한 것이라 할 수 있다. Neural Network에서도 마찬가지로 여러 prior를 바탕으로 다양한 regularization 방법들이 존재한다.
Weight Decay
- Prior: Weight의 값이 너무 크지 않을 것이다 (이를 model이 sharp하지 않고 smooth하다 라고 표현한다).
- Approach: 다음과 같은 형태로 optimization objective를 바꾼다.
- Gradient update rule은 다음과 같이 바뀐다
$$\min_w E(w) + \lambda w^\top w.$$
$$w(t+1) = w(t) (1 - 2 \eta \lambda) - \eta \nabla E (w(t)). $$
Smoothness and Noise Injection
Prior: Smoothness, $f(x)$와 $f(x+\varepsilon)$은 거의 비슷할 것이다.
Approach: noise에 대한 change를 줄이는 것은 곧, $\min \sum_i | \frac{\partial f(x_i)}{\partial x} |^2$ 과 같다.
- 따라서 위 식을 optimization function에 추가하여 문제를 풀게 되는데, Bishop 책에 따르면, 이 regularization term을 넣고 optimization하는 것은, random Gaussian noise를 input에 추가하여 learning하는 것과 equivalent하다는 것이 알려져 있으므로, input data에 random Gaussian noise를 섞는 것으로 대체할 수 있다.
Dropout (Hinton 2012)
- Prior: 하나의 classifier를 learning하는 것 보다, 여러 개의 classifier를 learning하고 이를 ensemble하여 classification하는 것이 더 좋다.
- Approach: 하나의 neural network 모델에서 여러 개의 모델을 learning할 수 있도록, NN의 node를 random하게 지운다. 이 경우 lower bound optimization과 같은 효과를 내기 때문에 조금 더 general한 model을 학습하는 것이 가능하며, dropout을 선택하는 것과 그렇지 않은 것은 약 10~20%의 성능 차이를 보인다. Drop하는 node는 보통 50%를 선택한다 (이 값도 제일 좋은 값을 learning해보려고 시도해봤는데 모두 0.5로 converge하였다고 한다).
Common Recipe for DNN.
세미나에서 박사님은 앞에서 살펴본 regularization과 optimization method들을 바탕으로 아래와 같은 common recipe를 제안하였다.
- Rectifier나 Maxout을 사용해라 (이 방법은 dropout처럼 값이 음수인 뉴런은 drop하고, 양수인 뉴런만 존재한다고 생각하면 계속 다른 NN을 사용하는 것처럼 생각할 수 있다. 이런 접근 방식을 사용하게 되면 differentiable하지는 않지만 sub-gradient를 사용하여 문제를 풀 수 있다고 한다).
- Preprocess data and choose features carefully (각 데이터 domain에 맞는 preprocessing을 취하자)
- Image: Whitening, Raw, SIFT, HoG?
- Speech: Raw? Spectrum?
- Text: Characters? words? tree? *General: z-Normalization?
- Dropout이나 다른 regularization method들을 사용하자.
- 데이터가 적은 경우라면 Unsuperviesd Pretraining (Hinton et al 2006) 을 사용해보자. 그러나 데이터가 많으면 오히려 나쁜 결과를 내게 되므로 쓰지 말자.
- Carefully search for hyperparameters (Random search, Bayesian optimization + Greedy search는 hyperparameter가 exponential하게 많으므로 불가능하다.)
- Often, deeper the better (이미지 - 레이어 7개 이상, 스피치 - 12개, 14개,…, 그 이외에는 hyper parameter라고 한다. 박사님은 2개부터 시작한다고 한다. + 참고로 지금 이미지에서는 VGG등의 최신 논문들은 19개까지 쌓기도 하고, Google의 Inception의 경우 어마어마하게 깊다.)
- Build an ensemble of neural networks
- Use GPU. (좋은 파워와 메인보드가 필요하고, 쿨링과 전기세를 조심하라고 조언해주셨다)
그러나 중요한 점은, 아무도 vanilla MLP (모든 layer가 fully connected layer인 NN)는 사용하지 않는다는 사실이다. 그 대신 domain knowledge가 많이 반영된 CNN이나 RNN등의 모델을 선택하여 사용한다. 최근 work들을 보면 Image등의 static한 데이터는 보통 CNN을 사용하고, sequencial data는 거의 RNN을 사용한다. CNN과 RNN에 대한 설명은 생략하도록 하겠다.
박사님은 deep learning의 좋은 점으로, 모델을 만들 때 부터 domain knowledge를 적용해서 CNN이나 RNN 등의 새로운 모델을 만들 수 있다는 점을 꼽았다. 만약 SVM 등의 기존 방법들을 사용한다면 모델 자체에서 그런 아이디어를 적용하지 어렵지만, deep learning은 그러기에 용이하다는 것이다. 예를 들어 Convolutional Neural Network의 Translation, Rotation, Temporal, Frequency invariance 등을 꼽을 수 있을 것이다. 이렇게 만든 CNN은, convolution layer와 pooling layer를 엄청나게 deep하게 쌓아 좋은 feature를 뽑아내고 마지막에 그것에 fully connected layer를 붙여서 linear classifier를 learning하는 방식으로 ‘deep’ CNN을 구성할 수 있다. 반면 RNN은 time을 길게 가져가는 방식으로 ‘deep’ RNN을 구성할 수 있는데, 이렇듯 ‘deep’하게 만드는 방식도 모델 특성을 따라가기 때문에 domain knowledge가 잘 반영된 모델이 deep해졌을 때도 잘 동작할 수 있는 것 같다고 생각한다.
나머지 part들
Unsupervised Learning 파트는 RBM, DNN 그리고 NADE에 대해 설명하고 마지막에 manifold leraning과 denoising autoencoder를 다루는 것으로 끝났다.
Advanced Topics 파트는 Deep Reinforcement Learning에 대해 다루고 (Atari 논문을 다뤘다), 당시에 막 연구가 되고 있던 NLP 연구에 대해 잠시 언급했다 (1년이 지난 지금은 NLP 쪽으로 많은 연구가 진행되었다). 그 밖에 optimization 관점에서, local minima라고 여겼던 부분이 사실 local minima가 아니라 flat한 부분이었다는 관측결과가 많이 나오고 있다는 말과, 적당하게 2nd order method를 섞으면 성능이 크게 향상된다는 말까지 언급하였다 (그러나 아직까지 2nd order optimization을 많이 사용하는 것 같지는 않다). 마지막으로 deep learning의 최대 약점으로 꼽히던 이론적인 분석 결과에 대해 많은 연구가 진행되고 있다는 얘기까지 잠깐 언급하고 세미나가 마무리 되었다.
정리
이 글은 내가 거의 1년 3개월 전에 들었던 세미나를 바탕으로 쓰여진 글이다. 박사님이 해주신 얘기도 많이 섞여있고 내 개인적인 의견도 많이 섞여있지만, 맨 처음 deep learning을 접할 때 큰 도움이 되었던 세미나인 만큼, 공유할 수 있으면 좋을 것 같아 정리해서 올려본다.