들어가며
Machine learning이라는 것을 접한지 어느새 거의 1년 반이 넘는 시간이 지났다. 많은 Machine learning 관련 글들을 써왔지만, 제대로 정리된 글이 없어 근래에 다시 머신러닝에 대해 공부를 하는 김에 제대로 정리해보기로 했다. 이번 8월부터 연구실에서 머신러닝 스터디를 하기로 한 김에 새로 다시 읽고 있는 Bishop 책을 중심으로 글을 작성할 것 같다. 나는 Machine Learning을 차근차근 공부하기에 적절한 자료가 없는 것이 항상 아쉬웠다. Lecture나 책이 있지만, 불필요하게 내용이 너무 많거나 처음 개념을 잡기에는 시간이 오래 걸리는 경우가 많았다. 또한 Machine Learning은 한글 자료도 많지 않다. 이 스터디에서는 최대한 내가 중요하다고 생각되는 기초적인 머신러닝 개념들에 대해 다룰 예정이다. 이 스터디 글은 머신러닝을 모르는 사람도 차근차근 순서대로 읽을 수 있도록 작성할 것이며 해당 주제를 이해하기 위해 필요한 ‘개념’ 설명 등에 집중하려고 한다. 앞서 말한대로 주로 Bishop을 중심으로 작성하게 될 것 같으며, 필요하면 다른 책이나 논문을 참고해서 글을 작성해보려 한다. 이 스터디에 작성하는 모든 표현들은 가급적 원래 단어를 영어로 쓰거나 한글 독음을 사용하여 작성할 것이다. 즉, Machine Learning은 머신러닝이나 Machine Learning으로 표기될 것이며, 거의 모든 경우에 기계학습으로 표기되지 않을 것이다.
What is Machine Learning?
본격적으로 첫 번째 글을 시작하기 전에 재미있는 짤방을 하나 보고 가자. 여러 사람들이 생각하는 Machine Learning이란?

재미있지 않은가? Machine Learning은 ‘기계를 학습시킨다’라는 의미이므로 일반적인 사람들이 생각하기에 마치 기계들을 모아놓고 수업을 하는 것 같은 모습을 연상하기 쉽다. 반면 다른 공학이나 과학을 전공하는 사람들의 입장에서는 AI를 연상하기 쉬우며, 특히 Machine이라는 뉘앙스 때문에 조금 더 Hardware에 focus된 것처럼 느끼기도 한다. 부모님은 자식이 구체적으로 무엇을 하는지는 모르겠지만 맨날 컴퓨터하고 서버 얘기하니까 IDS에서의 저런 모습을 생각할 수 있을 것 같다 ㅎㅎㅎ. 다른 프로그래머들은 뭔가 일반적인 프로그래밍과는 다르게 수학적으로 엄청 어려운 무언가를 하는 것 처럼 보이고 이상한 식들 막 적어놓고 ‘뭐야 저거 무서워’ 이런 느낌으로 바라보기 마련이다. 저 식은 아마도 error function과 관련된 식인 것 같다. 그리고 나는 내가 하는 일이 진짜 멋있는 일이라고 생각하지만 실제로 내가 하는건 남들이 만들어놓은 library를 import해서 사용하는게 전부라는 짤이다 ㅋㅋㅋ
이 하나의 짤방에서 참 많은 얘기들을 할 수 있을 것 같은데.. 일단 내가 앞으로 얘기할 Machine Learning이라는 것은 위의 그림에서 찾자면 what other programmers think I do와 흡사하다. 내가 대부분 알고리듬, 모델링 등 수학적인 것들에 관련된 부분을 다룰 것이기 때문이다. 자세한 얘기는 조금 더 뒤에서 하자.
What is Machine Learning? - Easy Answer
자 그러면 본론으로 들어가서 Machine Learning은 과연 무엇일까. Machine Learning은 컴퓨터에게 사람이 직접 명시적으로 Logic을 지시하지 않아도 데이터를 통해 컴퓨터가 ‘학습’을 하고 그것을 사용해 컴퓨터가 자동으로 문제를 해결하도록하는 것을 의미한다. 예를 들어 스팸메일을 자동으로 걸러내는 스팸필터를 만든다고 생각해보자. 가장 간단하게 생각할 수 있는 방법은 블랙리스트를 쓰는 것이다. 사용자들이 스팸이라고 많이 보고된 나쁜 발신자들을 모아서 블랙리스트에 추가하는 것이다. 하지만 이런 블랙리스트는 보내는 사람을 바꾸기만하면 우회하여 스팸을 보내기가 너무나 간단하다. 따라서 보낸 사람이 아니라 메일의 제목 혹은 내용으로 필터링을 해야한다. 역시 가장 간단한 방법은 단어의 블랙리스트를 만드는 것이다. 예를 들어 ‘광고’, ‘싸게’ 등의 단어들이 포함되면 해당 메일을 스팸으로 분류하는 것이다. 하지만 이 방법역시 우회하기 쉬울 뿐더러 (광.고. 라고 쓴다거나) 일상 생활에서도 쓰일 수 있는 표현이 있을 수 있기 때문에 멀쩡한 사람의 email을 spam이라고 인식하게 되는 끔찍한 일이 벌어질 수 있다. 이 문제를 Machine Learning으로 해결해보자. 그렇게 하면 컴퓨터에게 스팸인 email과 스팸이 아닌 email들을 주고, 스팸인 email들이 왜 스팸인지 ‘Learning’을 시켜서 ‘데이터를 통해 컴퓨터가 자동으로 판별을 해’ 스팸을 걸러내는 방식을 취하게 할 수 있다. 이렇게 스팸 필터를 만들게 될 경우 데이터가 많아질수록 더 많은 것들을 ‘Learning’할 수 있으므로 스팸 필터의 performance역시 증가하게 될 것이다.
머신러닝은 이렇게 ‘기계’가 일일이 코드로 명시하지 않은 동작을 데이터로부터 ‘학습’하여 실행할 수 있도록 하는 ‘알고리즘’을 개발하는 연구 분야이다. (1959년 아서 사무엘)
What is Machine Learning? - Deep Answer
조금 더 엄밀하게 Machine Learning을 정의해보자. Machine Learning problem은 아래 요소들로 구성이 된다.
- Experience E를 Learning할 Computer Program
- 각각의 E에 대응되는 class of task T
- Task의 Performace Measure P
위에서 기술한 세 가지 요소들로부터 Machine Learning problem을 다음과 같이 정의할 수 있다. ‘Experience $E$를 사용하여 (Learning하여) task $T$의 performance $P$가 개선이 되도록 하는 program (Algorithm)’. 다시 말해서 머신러닝 문제는 어떤 task $T$를 풀기 위한 알고리즘을 개발하는 분야인데 이 알고리즘의 performance measure가 ‘기계’ 혹은 Compute program이 ‘Learning’할 수 있는 Experience $E$를 사용해 개선될 수 있는 알고리즘을 개발하는 문제인 것이다. 스팸필터 문제로 돌아가보자. 스팸필터 문제에서 해결하고자 하는 Task는 새로운 메일을 받았을 때 해당 메일이 스팸메일인지 아니면 그렇지 않은지 판별하는 것이다. 따라서 algorithm의 performance measure $P$는 얼마나 정확하게 스팸을 골라냈는지 accuracy를 측정하면 간단하게 구할 수 있다. 또한 Experiment $E$는 예전에 받았던 이메일 들이 될 것이다. 또한 블랙리스트 등은 데이터가 많다고 해서 그 성능이 개선되는 것이 아니기 때문에 머신러닝이라고 할 수 없다. 우리가 하고 싶은 것은, 스팸인지 아닌지 판별하기 위해 예전 이메일들로 스팸 필터를 ‘학습’ 시켜서 스팸 필터의 성능을 향상시키는 것이다.
Machine Learnig이 하는 일은 주어진 ‘데이터’ $X = (x_1, x_2, x_3, \ldots, x_n)$와 각 데이터에 대응하는 실제 ‘현상’ $Y = (y_1, y_2, \ldots, y_n) $에 대한 ‘관계’ function $f$를 찾는 과정과 같다. 정확한 함수 $f$를 찾기 위해 Machine Learnig 알고리즘들은 데이터에 대한 가정을 하고, 그 가정에 따라 주어진 데이터를 ‘최대한 잘 설명할 수 있는’, 함수 $f’$을 찾는다. 이때 이런 $f’$을 Hypothesis라고 한다.
Problem Setting
Machine Learning 문제를 풀기 위해서는 다음과 같은 것들이 필요하다.
- Set of possible instance(domain): X
- Output: Y
Unknown target function $f:X \to Y$
Set of hypothesis function space $H \subset \{h|h:X \to Y\}$
Input
Traing example $\{ \langle x_i, y_i \rangle \}$
Output
$h\in H$ that best approximates target function f with some performance measure
Problem Setting의 네 번째 요소인 set of function hypothesis space는 모든 function들을 확인하는 것은 불가능하기 때문에 찾고자하는 function들의 set으로만 한정을 짓기 위해 필요하다. 이런 problem setting이 완료되고 나면 learning을 하기 위한 input data가 필요한데 이를 training data라고 한다. training data는 $\{ \langle x_i, y_i \rangle \}$ 식으로 주어지는데, 만약 label $y$가 주어지는 경우는 supervised learning, 주어지지 않는 경우는 unsupervised learning이라고 한다. 마지막으로 Machine Learning Algorithm의 output으로 $h\in H$ 인 h 중에서 target function f와 가장 유사한 hypothesis를 return하게 된다.
위에서 설명한 얘기를 그림으로 설명하면 아래와 같은 그림을 그릴 수 있다.
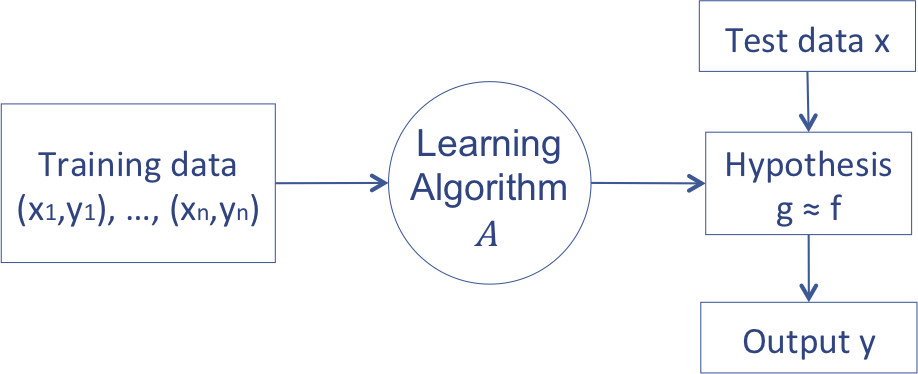
다시 한 번 스팸필터를 생각해보자. 데이터 X는 메일들이다. 우리가 받는 메일 하나하나가 데이터가 될 수도 있고, 그 메일 안에 있는 단어 하나하나가 될 수도, 혹은 아예 알파벳 하나하나가 될 수도 있다. 그것은 우리가 정하기 나름이니까. 현상 Y는 각각의 메일이 스팸인지, 아니면 일반 메일인지 구분하는 구분자, indicator, 혹은 Label, Class가 될 것이다. 마지막으로 데이터에 대한 가정을 통해 Hypothesis function space를 결정하고 그 function을 찾는 알고리즘을 적용하는 것이다.
Why Machine Learning?
Machine Learning은 왜 사용하는 것일까? 만약 우리가 찾고자하는 것이 아주 간단한 함수이고, 머신러닝 기법을 사용하지 않고도 찾을 수 있다면 머신러닝을 꼭 사용할 필요는 없을 것이다. 그러나 만약 찾고자하는 함수가 매우 복잡하고 어렵다면 머신러닝은 아주 유용하게 쓰일 수 있다. 머신러닝 문제는 결국 어떤 상황을 해결하기 위한 문제를 세우고 그 문제를 풀기 위한 모델을 만들기 위해 데이터에 대한 가설을 세우고, 그 가설에 부합하는 알고리즘을 개발하는 과정이다. 따라서 우리가 명시적으로 문제 해결하는 방법을 결정하는 것이 아니라, 그 대신 문제를 해결하는 방법을 알려주고, 문제는 컴퓨터가 풀도록 할 수 있다. 머신러닝을 사용해 아주 많은 문제들을 풀 수 있다. 계속 예시로 든 스팸필터도 있고, 쇼핑 이력을 보고 고객이 어떤 물건을 더 사고 싶어할지 추천하거나 광고를 할 수도 있다. 날씨와 고속도로의 교통상황의 상관관계를 찾을 수도 있다. 즉, Machine Learning Problem의 형태에 맞게 문제를 만들고, 그 문제를 풀기 위한 데이터와 데이터에 대한 가설만 있다면 그 어떤 문제도 해결할 수 있는 것이다.
또한 최근 들어서 Machine Learning이 급부상하고 있는 가장 큰 이유 중 하나는 ‘빅데이터’이다. 과거와는 비교할 수 없을 정도로 데이터가 많아졌는데, 그 데이터에서 사람이 ‘의미’를 일일이 뽑아내기 너무 어렵기 때문이다. 이에 사람이 데이터를 분석하기보다는 기계에게 데이터를 학습시켜 알아서 문제를 판단하게 할 수 있으면 좋겠다라는 needs가 발생하였고, 이에 사람들이 Machine Learning을 많이 요구하게 되었다. 또한 Machine Learning Algorithm은 input data가 많으면 많을수록 성능이 좋아진다. 요즘같은 ‘빅데이터’가 부상하는 시기에 이만큼 적절한 기술도 찾기 힘들 것이다.
Class of Machine Learning
Machine Learning은 정말 많은 분야를 포함하는 정말 큰 연구 분야이다. 하지만 그럼에도 일반적으로 Machine Learning은 Supervised Learning, Unsupervised Learning, Reinforcement Learning 세 가지로 분류할 수 있다. 앞서 설명한 것처럼 Supervised Learning, Unsupervised Learning의 차이점은 training data에 label이 있느냐 없느냐의 차이이다. Reinforcement Learning은 앞에서 다룬 두 문제와는 다소 다르다. 조금 복잡하기 때문에 이 스터디의 맨 마지막에 간단하게 다루도록 하겠다.
변경 이력
- 2014년 8월 2일: 글 등록
- 2014년 8월 19일: 오탈자 수정, 예시 추가
- 2014년 10월 4일: 글 구성 변경. 그림 등 추가
- 2015년 2월 28일: 변경 이력 추가 및 내용 revise
- 2015년 9월 13일: problem setting 조건 변경 ($\in$을 $\subset$으로)
Machine Learning 스터디의 다른 글들
- Machine Learning이란?
- Probability Theory
- Overfitting
- Algorithm
- Decision Theory
- Information Theory
- Convex Optimzation
- Classification Introduction (Decision Tree, Naïve Bayes, KNN)
- Regression and Logistic Regression
- PAC Learning & Statistical Learning Theory
- Support Vector Machine
- Ensemble Learning (Random Forest, Ada Boost)
- Graphical Model
- Clustering (K-means, Gaussian Mixture Model)
- EM algorithm
- Hidden Markov Model
- Dimensionality Reduction (LDA, PCA)
- Recommendation System (Matrix Completion)
- Neural Network Introduction
- Deep Learning 1 - RBM, DNN, CNN
- Reinforcement Learning