Sanghyuk Chun (He/Him)
Sanghyuk Chun
- Ph.D. Student (2025-Present)
- Princeton University
- sanghyukc [at] princeton.edu
- Google Scholar | Github | Twitter | CV

I am a Ph.D. student at Princeton University advised by Professor Olga Russakovsky. My current research interest lies on the domains of machine learning, multi-modal learning (e.g., vision-language, language-audio, and audio-visual), trustworthy ML, and computer vision.
Prior to Princeton, I served as a lead research scientist at ML Research team in NAVER AI Lab (from 2018 to 2025). I held a position as a research engineer at KAKAO Corp from 2016 to 2018, where my work focused on recommendation systems and machine learning applications.News
- _5/2026 : Being nominated as CVPR 2026 outstanding reviewers (top 5%) [link].
- _4/2026 : 1 paper [Multiplicity] is accepted at the ICML position track
- _4/2026 : ReFINE recieved the best paper award at ICLR Workshop on Test-Time Updates (TTU)!
- _3/2026 : 1 paper [ReFINE] is accepted at ICLR Workshop on Test-Time Updates (TTU) and selected as Oral presentation!
- _1/2026 : Serving as an area chair at ICML 2026
See older news
- _8/2025 : Serving as an area chair at ICLR 2026
- _8/2025 : Serving as an area chair at AISTATS 2026
- _8/2025 : 1 paper [VoxStudio] is accepted at ICCV 2025 Gen4AVC workshop.
- _7/2025 : Starting a new chapter in life at Princeton University 👨🎓, with the great honor of being awarded the Upton Fellowship — a short blog post about my decision: [link]
- _6/2025 : 1 paper [RTD] is accepted at ICCV 2025.
- _6/2025 : Being nominated as CVPR 2025 outstanding reviewers (711/12,593 = 5.6%) [link].
- _5/2025 : Giving a talk at Sogang University (topic: Multiplicity in Multimodal Learning) [slide]
- _4/2025 : 1 paper [ReadabilityEmergence] is accepted at 2nd Workshop on Emergent Visual Abilities and Limits of Foundation Models at CVPR 2025.
- _4/2025 : Giving a talk at Yonsei University (topic: Towards Reliable and Efficient Multimodal AI) [slide]
- _3/2025 : 1 paper [LongProLIP] is accepted at ICLR 2025 Workshop on Quantify Uncertainty and Hallucination in Foundation Models: The Next Frontier in Reliable AI.
- _2/2025 : Serving as an area chair at NeurIPS 2025
- _1/2025 : 1 paper [ProLIP] is accepted at ICLR 2025.
- _1/2025: Reaching a research milestone of 10,000 citations at Google Scholar!
- 12/2024 : Giving a talk at POSTECH AI Day (topic: Probabilistic Language-Image Pre-training) [slide]
- 12/2024 : Serving as an area chair at ICML 2025
- 12/2024 : 1 paper [ReWaS] is accepted at AAAI 2025.
- 11/2024 : 1 paper [FairDRO extension] is accepted at Neural Networks.
- 10/2024 : 1 paper [ReWaS] is accepted at NeurIPS 2024 Workshopon Video-Language Models.
- 10/2024 : Serving as an area chair at AISTATS 2025
- _9/2024 : 1 paper [CKD] is accepted at NeurIPS 2024 D&B track.
- _9/2024 : Giving a talk at SKKU (topic: "Realistic challenges and limitations of AI") [slide]
- _8/2024 : 1 paper[RoCOCO] is accepted at ECCV 2024 Synthetic Data for Computer Vision Workshop and selected as Oral presentation!
- _8/2024 : Giving a talk at HUST AI Summer School on "Generative AI" (topic: "CompoDiff") [slide]
- _8/2024 : Serving as an area chair at ICLR 2025
- _8/2024 : HYPE[HYPE] is selected as Oral presentation at this ECCV!
- _7/2024 : 1 paper [CompoDiff] is accepted at TMLR.
- _7/2024 : 3 papers [HYPE][SAT][LUT] are accepted at ECCV 2024.
- _4/2024 : 1 paper [CompoDiff] is accepted at CVPR 2024 SynData4CV Workshop.
- _4/2024 : Serving as an area chair at NeurIPS 2024 Datasets and Benchmarks Track.
- _3/2024 : Serving as an area chair at NeurIPS 2024.
- _3/2024 : 1 paper [RegionVLP] is accepted at NAACL 2024 main track.
- _3/2024 : Giving a talk at UNIST (topic: "Probabilistic Image-Text Representations") [slide]
- _2/2024 : 1 paper [LinCIR] is accepted at CVPR 2024.
- _2/2024 : Giving a talk at IEIE AI Signal Processing Society Winter School (topic: "Probabilistic Image-Text Representations") [slide]
- _1/2024 : 2 papers [PCME++][AD Correctness] are accepted at ICLR 2024. One paper[PCME++] is my sole authored paper 🤗, and one paper[AD Correctness] is selected as spotlight! (Top-5% paper)
- 12/2023 : Giving a talk at Dankook University (topic: "Probabilistic Image-Text Representations") [slide]
- 12/2013: We finally released SynthTriplets18 dataset!
- 11/2013: Being nominated as NeurIPS 2023 top reviewers (10%) [link].
- _9/2023 : Giving a talk at HUST AI Summer School on "Modern Machine Learning: Foundations and Applications" (topic: "Probabilistic Image-Text Representations") [slide]
- _9/2023 : 1 paper [PCME++ short] is accepted at the non-archival track of ICCV 2023 Workshop on Closing The Loop Between Vision And Language (CLVL).
- _8/2023 : Giving a talk at Yonsei University (topic: "CompoDiff: Versatile Composed Image Retrieval With Latent Diffusion") [slide]
- _7/2023 : 1 paper [SeiT] is accepted at ICCV 2023.
- _7/2023 : Serving as a TMLR Action Editor.
- _6/2023 : Being nominated as a TMLR Expert Reviewer [link].
- _6/2023 : Giving a talk at Sogang University (topic: "Probabilistic Image-Text Representations") [slide]
- _5/2023 : Serving as an area chair at NeurIPS 2023 Datasets and Benchmarks Track.
- _4/2023 : We released "Graphit: A Unified Framework for Diverse Image Editing Tasks" [GitHub] [Graphit], The technical report will be released soon!
- _4/2023 : 1 paper [3D-Pseudo-Gts] is accepted at CVPR 2023 Workshop on Computer Vision for Mixed Reality (CV4MR).
- _1/2023 : 1 paper [FairDRO] is accepted at ICLR 2023.
- _9/2022 : Giving a talk at Sogang University (topic: "ECCV Caption") [slide]
- _9/2022 : 1 paper [MSDA theorem] is accepted at NeurIPS 2022.
- _8/2022 : Starting a new chapter in life with Song Park 🤵❤️👰.
- _7/2022 : 1 paper [LF-Font journal] is accepted at IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI).
- _7/2022 : 2 papers [ECCV Caption] [MIRO] are accepted at ECCV 2022.
- _7/2022 : Giving a talk at UNIST AIGS (topic: "Towards Reliable Machine Learning: Challenges, Examples, Solutions") [slide]
- _6/2022 : Giving a tutorial on "Shortcut learning in Machine Learning: Challenges, Analysis, Solutions" at FAccT 2022. [ tutorial homepage | slide | video ]
- _5/2022 : Receiving an outstanding reviewer award at CVPR 2022 [link].
- _5/2022 : 1 paper [DCC] is accepted at ICML 2022.
- _4/2022 : 1 paper [WSOL Eval journal] is accepted at IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI).
- _4/2022 : Organizing ICLR 2022 ML in Korea Social
- _3/2022 : Giving guest lectures at KAIST and SNU (topic: "Towards Reliable Machine Learning") [slide]
- _3/2022 : Co-organizing FAccT 2022 Translation/Dialogue Tutorial: "Shortcut learning in Machine Learning: Challenges, Analysis, Solutions" (slides, videos and web pages will be released soon)
- _3/2022 : 1 paper [CGL] is accepted at CVPR 2022.
- _2/2022 : Giving a talk at POSTECH AI Research (PAIR) ML Winter Seminar 2022 (topic: "Shortcut learning in Machine Learning: Challenges, Examples, Solutions") [slide]
- _1/2022 : 2 papers [ViDT] [WCST-ML] are accepted at ICLR 2022.
- 12/2021 : Co-hosting NeurIPS'21 workshop on ImageNet: Past, Present, and Future with 400+ attendees!
- 12/2021 : Giving a talk at University of Seoul (topic: "Realistic challenges and limitations of AI") [slide]
- 11/2021 : Giving a talk at NAVER and NAVER Labs Europe (topic: Mitigating dataset biases in Real-world ML applications) [slide]
- 11/2021 : Giving a guest lecture at UNIST (topic: Limits and Challenges in Deep Learning Optimizers) [slide]
- 10/2021 : Releasing an unified few-shot font generation framework! [code]
- _9/2021 : 2 papers [SWAD] [NHA] are accepted at NeurIPS 2021.
- _8/2021: Reaching a research milestone of 1,000 citations at Google Scholar and Semantic Scholar!
- _7/2021 : Co-organizing the NeurIPS Workshop on ImageNet: Past, Present, and Future! [webpage]
- _7/2021 : 2 papers [MX-Font] [PiT] are accepted at ICCV 2021.
- _7/2021 : Giving a talk at Computer Vision Centre (CVC), UAB (topic: PCME and AdamP) [info] [slide]
- _6/2021 : Giving a talk at KSIAM 2021 (topic: AdamP). [slide]
- _6/2021 : Giving a guest lecture at Seoul National University (topic: few-shot font generation) .[slide]
- _5/2021 : Receiving an outstanding reviewer award at CVPR 2021 [link].
- _4/2021 : 1 paper [LF-Font] is accepted at CVPR 2021 workshop (also appeared at AAAI).
- _3/2021 : 2 papers [PCME] [ReLabel] are accepted at CVPR 2021.
- _1/2021 : 1 paper [AdamP] is accepted at ICLR 2021.
- 12/2020 : 1 paper [LF-Font] is accepted at AAAI 2021.
- _7/2020 : 1 paper [DM-Font] is accepted at ECCV 2020.
- _6/2020 : Receiving the best paper runner-up award at AICCW CVPR 2020 [DM-Font WS].
- _6/2020 : Receiving an outstanding reviewer award at CVPR 2020 [link].
- _6/2020 : Giving a talk at CVPR 2020 NAVER interative session.
- _6/2020 : 1 paper [ReBias] is accepted at ICML 2020.
- _4/2020 : 1 paper [DM-Font short] is accepted at CVPR 2020 workshop.
- _2/2020 : 1 paper [wsoleval] is accepted at CVPR 2020.
- _1/2020 : 1 paper [HCNN] is accepted at ICASSP 2020.
- 10/2019 : 1 paper [HCNN short] is accpeted at ISMIR late break demo.
- 10/2019 : Working at Naver Labs Europe as a visiting researcher (Oct - Dec 2019)
- _7/2019 : 2 papers [CutMix] [WCT2] are accepted at ICCV 2019 (1 oral presentation).
- _6/2019 : Giving a talk at ICML 2019 Expo workshop.
- _5/2019 : 2 papers [MTSA] [RegEval] are accepted at ICML 2019 workshops (1 oral presentation).
- _5/2019 : Giving a talk at ICLR 2019 Expo talk.
- _3/2019 : 1 paper [PRM] is accepted at ICLR 2019 workshop.
Current Service Appointments
- Area Chair - ICML 2026 ICLR 2026 AISTATS 2026
- Action Editor - TMLR
- Reviewer - NeurIPS 2026 Workshop Proposals ECCV 2026 CVPR 2026
Research
I am interested in machine learning and its reliability. My research philosophy aims to (1) scalability and (2) theoretical or conceptual soundness. I have been particularly interested in the following research directions (but not limited to):
-
Multiplicity and Diversity in Multimodal representation learning. We often assume a single ground truth when building datasets, training models, and evaluating model performance. However, many multimodal tasks actually have multiple plausible interpretations, matches, captions, or decisions [C36]. My recent research aims to address this challenge: Chun, et al., 2026 [A9], Chun and Russakovsky, 2026 [C36], Chun, et al., 2025, [C34], and more. (click to see more)
- Multiplicity is an inevitable and inherent challenge in multimodal learning [Chun and Russakovsky, 2026. C36]. My previous study on MS-COCO Caption showed that there exist a lot of plausible hidden positives which are treated as negatives (so called "False Negatives") [Chun, et al., 2022. C21].
- I've worked on addressing this issue in model training by probabilistic frameworks (named probabilistic embeddings) [Chun, et al., 2021. C11], [Chun, 2024. C25], [Chun, et al., 2025. C34], [Chun and Yun, 2025. W11]. Notably, PCME [C11] is the first probabilistic embeddings work in this field, and ProLIP [C34] is the first large-scale pre-trained probabilistic model competitive with the state-of-the-art vision-language models.
- Multiplicity also affects to dataset construction. In HYPE [Kim, et al., 2024. C31], we showed that collecting image-text pairs based on "specificity" (which is a similar concept with multiplicity) can outperform the existing state-of-the-art dataset filtering methods using external models with large-scale pre-training.
- One way to control multiplicity is to give more specific descriptions or instructions to the given inputs. For example, by conditioning with more instructions, we may achieve a more specified representation of the given input. With this principle, I actively worked on composed image retrieval (CIR), which is a conditional retrieval with a text instruction. I authored a few milestone works in zero-shot CIR [Gu and Chun, et al. 2024. J3], [Gu and Chun, et al. 2024. C27], and a post-hoc improvement method [Byun and Jeong, et al. 2025. C35]. Although I don't actively work this field as of now, I still think this is an interesting approach to address the problem.
- Recently, I have extended this perspective to uncertainty estimation in multimodal large language models. In Chun, et al., 2026 [A9], we showed that MLLM uncertainty can be decomposed into context-specific and multiplicity-specific components. This decomposition shows that multiplicity is a structured source of uncertainty, and enables more reliable and efficient uncertainty estimation.
-
Reliable machine learning. Our model should not learn undesirable shortcut features [ReBias] [Shortcut learning] [Shortcut learning tutorial], or should be robust to unseen corruptions [CutMix] [RegEval] [ReLabel] [PiT] or significant distribution shifts [SWAD] [MIRO]. Also we need to make a machine not discriminative to certain demographic groups [CGL] [FairDRO]. We expect a model says "I don't know" when they get unexpected inputs [PCME] [PCME++] [ProLIP] [CoMet]. At least, we expect a model can explain why it makes a such decision [MTSA] [MTSA WS] [WSOL eval] [WSOL Eval journal], how different model design choices will change model decisions [NetSim] and how it can be fixed (e.g., More data collection? More annotations? Filtering?). My research focuses on expanding machine knowledge from "just prediction" to "logical reasoning". (click to see more)
- Representative topics and projects: Shortcut / Bias (ICML'20 [C6], ICLR'22 [C16]), Domain generalization (NeurIPS'21 [C15], ECCV'22 [C20]), Reliable Evaluation (CVPR'20 [C5], TPAMI'22 [J1], ECCV'22 [C21], ECCV WS'24 [W9]), Algorithmic Fairness (CVPR'22 [C18], ICLR'23 [C23], NeurIPS'24 [C32], Neural Networks'25 [J4]) Adversarial Attack/Defense (ICLR WS'19 [W1], ECCV'24 [C30]), Robustness (ICML WS'19 [W3], ICCV'19 [C3], ArXiv'21 [A4]), and Uncertainty Estimation (ICLR'25 [C34], ArXiv'25 [A9]).
- In this research direction, what I value most is whether a method is grounded in a clear theoretical or conceptual motivation. Since reliability problems often arise from hidden failure modes, purely heuristic fixes may improve benchmark numbers without actually addressing the underlying issue. Therefore, my main focus is to understand why a model fails, what problem a method is supposed to solve, and whether the proposed approach can address that problem in a principled way.
Representative works that reflect my research approach and significant contributions are highlighted, with the most significant works emphasized in orange.
(C: peer-reviewed conference, W: peer-reviewed workshop, A: arxiv preprint, O: others)
(❋authors contributed equally)
See also at my Google Scholar.
2026
- CoMet: Context and Multiplicity Decomposition for Multimodal Uncertainty Estimation.
- Multiplicity is an Inevitable and Inherent Challenge in Multimodal Learning.
- Reinforced Fast Weights with Next-Sequence Prediction. Oral presentation The best paper award
2025
- Mitigating Cross-Image Information Leakage in LVLMs for Multi-Image Tasks.
- Seeing What You Say: Expressive Image Generation from Speech.
- An Efficient Post-hoc Framework for Reducing Task Discrepancy of Text Encoders for Composed Image Retrieval.
- Emergence of Text Readability in Vision Language Models.
-
LongProLIP: A Probabilistic Vision-Language Model with Long Context Text.
- Sanghyuk Chun, Sangdoo Yun
- ICLR 2025 QUESTION Workshop. paper | code | pre-trained models 🤗 | slide | bibtex
- DNNs May Determine Major Properties of Their Outputs Early, with Timing Possibly Driven by Bias.
-
Probabilistic Language-Image Pre-Training.
- Sanghyuk Chun, Wonjae Kim, Song Park, Sangdoo Yun
- ICLR 2025. paper | code | pre-trained models 🤗 | slide | bibtex
-
Read, Watch and Scream! Sound Generation from Text and Video.
- Yujin Jeong, Yunji Kim, Sanghyuk Chun, Jiyoung Lee
- AAAI 2025. NeurIPS 2024 Workshop on Video-Language Models. paper | code | project page | bibtex
- FairDRO: Group Fairness Regularization via Classwise Robust Optimization.
2024
-
Do Counterfactually Fair Image Classifiers Satisfy Group Fairness? -- A Theoretical and Empirical Study.
- Sangwon Jung❋, Sumin Yu❋, Sanghyuk Chun†, Taesup Moon†
- NeurIPS 2024 D&B. paper | code and dataset | bibtex
- HYPE: Hyperbolic Entailment Filtering for Underspecified Images and Texts. Oral presentation
- Similarity of Neural Architectures using Adversarial Attack Transferability.
- Learning with Unmasked Tokens Drives Stronger Vision Learners.
- RoCOCO: Robustness Benchmark of MS-COCO to Stress-Test Image-Text Matching Models. Oral presentation
- CompoDiff: Versatile Composed Image Retrieval With Latent Diffusion.
- Toward Interactive Regional Understanding in Vision-Large Language Models
- Language-only Efficient Training of Zero-shot Composed Image Retrieval.
- What Does Automatic Differentiation Compute for Neural Networks? Spotlight presentation
-
Improved Probabilistic Image-Text Representations.
- Sanghyuk Chun
- ICLR 2024. ICCV CLVL 2023. paper | code | project page | slide | bibtex
2023
- SeiT: Storage-Efficient Vision Training with Tokens Using 1% of Pixel Storage.
- Three Recipes for Better 3D Pseudo-GTs of 3D Human Mesh Estimation in the Wild.
- Re-weighting based Group Fairness Regularization via Classwise Robust Optimization.
2022
- Group Generalized Mean Pooling for Vision Transformer.
- A Unified Analysis of Mixed Sample Data Augmentation: A Loss Function Perspective.
-
ECCV Caption: Correcting False Negatives by Collecting Machine-and-Human-verified Image-Caption Associations for MS-COCO.
- Sanghyuk Chun, Wonjae Kim, Song Park, Minsuk Chang, Seong Joon Oh
- ECCV 2022. paper | code | pypi | slide (short talk) | slide (long talk) | bibtex
- Domain Generalization by Mutual-Information Regularization with Pre-trained Models.
-
Few-shot Font Generation with Weakly Supervised Localized Representations.
- Song Park❋, Sanghyuk Chun❋, Junbum Cha, Bado Lee, Hyunjung Shim
- IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI) 2022. (IF:24.314)
- PAMI. paper | code (old) | code (new) | project page | bibtex
-
Evaluation for Weakly Supervised Object Localization: Protocol, Metrics, and Datasets.
- Junsuk Choe❋, Seong Joon Oh❋, Sanghyuk Chun, Seungho Lee, Zeynep Akata, Hyunjung Shim
- IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI) 2022. (IF:24.314)
- PAMI. paper | code and dataset | bibtex
- An Extendable, Efficient and Effective Transformer-based Object Detector.
- Dataset Condensation with Contrastive Signals.
- Learning Fair Classifiers with Partially Annotated Group Labels.
- ViDT: An Efficient and Effective Fully Transformer-based Object Detector.
- Which Shortcut Cues Will DNNs Choose? A Study from the Parameter-Space Perspective.
2021
- SWAD: Domain Generalization by Seeking Flat Minima.
- Neural Hybrid Automata: Learning Dynamics with Multiple Modes and Stochastic Transitions.
- StyleAugment: Learning Texture De-biased Representations by Style Augmentation without Pre-defined Textures.
- Rethinking Spatial Dimensions of Vision Transformers.
- Multiple Heads are Better than One: Few-shot Font Generation with Multiple Localized Experts.
-
Probabilistic Embeddings for Cross-Modal Retrieval.
- Sanghyuk Chun, Seong Joon Oh, Rafael Sampaio de Rezende, Yannis Kalantidis, Diane Larlus
- CVPR 2021. paper | code | video | slide (short talk) | slide (long talk) | bibtex
- Re-labeling ImageNet: from Single to Multi-Labels, from Global to Localized Labels.
- AdamP: Slowing Down the Slowdown for Momentum Optimizers on Scale-invariant Weights.
-
Few-shot Font Generation with Localized Style Representations and Factorization.
- Song Park❋, Sanghyuk Chun❋, Junbum Cha, Bado Lee, Hyunjung Shim
- AAAI 2021. CVPR Workshop 2021. paper | code | project page | bibtex
2020
- Few-shot Compositional Font Generation with Dual Memory.
- Learning De-biased Representations with Biased Representations.
- Toward High-quality Few-shot Font Generation with Dual Memory. Oral presentation The best paper runner-up award
-
Evaluating Weakly Supervised Object Localization Methods Right.
- Junsuk Choe❋, Seong Joon Oh❋, Seongho Lee, Sanghyuk Chun, Zeynep Akata, Hyunjung Shim
- CVPR 2020. paper | code and dataset | tweet | slide | video on CVPR | video on ECCV tutorial | bibtex
-
Data-driven Harmonic Filters for Audio Representation Learning.
- Minz Won, Sanghyuk Chun, Oriol Nieto, Xavier Serra
- ICASSP 2020. paper | code and pretrained models | video | bibtex
2019
- Neural Approximation of Auto-Regressive Process through Confidence Guided Sampling.
-
Toward Interpretable Music Tagging with Self-attention.
- Minz Won, Sanghyuk Chun, Xavier Serra
- preprint. paper | code and pretrained models | bibtex
-
CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features. Oral presentation
- Sangdoo Yun, Dongyoon Han, Seong Joon Oh, Sanghyuk Chun, Junsuk Choe, Youngjoon Yoo
- ICCV 2019. paper | code and pretrained models | blog | bibtex
-
Photorealistic Style Transfer via Wavelet Transforms.
- Jaejun Yoo❋, Youngjung Uh❋, Sanghyuk Chun❋, Byungkyu Kang, Jung-Woo Ha
- ICCV 2019. paper | code and model weights | video | blog | bibtex
- Automatic Music Tagging with Harmonic CNN.
- An Empirical Evaluation on Robustness and Uncertainty of Regularization methods.
-
Visualizing and Understanding Self-attention based Music Tagging. Oral presentation
- Minz Won, Sanghyuk Chun, Xavier Serra
- ICML Workshop 2019. paper | code | talk video | bibtex
- Where To Be Adversarial Perturbations Added? Investigating and Manipulating Pixel Robustness Using Input Gradients.
~ 2018
-
Multi-Domain Processing via Hybrid Denoising Networks for Speech Enhancement.
- Jang-Hyun Kim❋, Jaejun Yoo❋, Sanghyuk Chun, Adrian Kim, Jung-Woo Ha
- preprint. paper | project page | bibtex
- A Study on Intelligent Personalized Push Notification with User History.
-
Scalable Iterative Algorithm for Robust Subspace Clustering: Convergence and Initialization.
- Master's Thesis, Korea Advanced Institute of Science and Technology, 2016 (advised by Jinwoo Shin) paper | code
Academic Activities
Professional Service
- Journal Action Editor:
- Conference Area Chair:
- ICLR 2025-2026
- AISTATS 2025-2026
- NeurIPS 2024-2025
- NeurIPS Dataset and Benchmark (D&B) track 2023-2024
- ICML 2025-2026
- Tutorial / Workshop / Social Organizer:
- FAccT 2022 Translation/Dialogue Tutorial: "Shortcut learning in Machine Learning: Challenges, Analysis, Solutions"
-
NeurIPS 2021 Workshop on ImageNet: Past, Present, and Future
- Co-organized by Zeynep Akata, Lucas Beyer, Sanghyuk Chun, Almut Sophia Koepke, Diane Larlus, Seong Joon Oh, Rafael Sampaio de Rezende, Sangdoo Yun, Xiaohua Zhai
- ICLR 2021 Social: ML in Korea, technical chair and session chair
- ICLR 2022 Social: ML in Korea, a main organizer
- Reviewer:
- Conference: ICML 2021-2024, NeurIPS 2020-2023 (NeurIPS 2023 Top reviewer), ICLR 2021-2024, AAAI 2021, CVPR 2020-2026 (CVPR 2020, 2021, 2022, 2025, 2026 Outstanding reviewer), ICCV/ECCV 2021-2026, WACV 2021, ACCV 2020, CHI 2023
- Proposals: NeurIPS Workshop Proposals 2026
- Journal: Transactions on Machine Learning Research (TMLR) (TMLR 2023 Expert Reviewer), Transactions on Pattern Analysis and Machine Intelligence (TPAMI), International Journal of Computer Vision (IJCV), IEEE Transactions on Image Processing (TIP)
Honors and Awards
- Outstanding reviewer award, CVPR 2026
- Best paper award, Workshop on Test-Time Updates at ICLR 2026
- Francis Robbins Upton Fellowship in Engineering, Princeton University (2025)
- Outstanding reviewer award, CVPR 2025
- Top reviewer, NeurIPS 2023
- TMLR Expert Reviewer (2023)
- Outstanding reviewer award, CVPR 2022
- Outstanding reviewer award, CVPR 2021
- Outstanding reviewer award, CVPR 2020
- Best paper runner-up award, AI for Content Creation Workshop at CVPR 2020
Talks
- "Multiplicity in Multimodal Learning: From Ambiguity to Understanding", Sogang University (2025) [slide]
- "Towards Reliable and Efficient Multimodal AI", Yonsei University (2025) [slide]
- "Probabilistic Language-Image Pre-training", POSTECH AI Day (2024) [slide]
- "Realistic challenges and limitations of AI", SKKU (2024). [slide]
- "CompoDiff: Versatile Composed Image Retrieval With Latent Diffusion", HUST AI Summer School on "Generative AI" (2024). [slide]
- "Font Generation", Dankook University (2024).
- "Probabilistic Image-Text Representations", IEIE AI Signal Processing Society Winter School and UNIST AIGS Seminar (2024). [slide]
See older talks
- "Probabilistic Image-Text Representation", HUST AI Summer School on "Modern Machine Learning: Foundations and Applications" and Dankook University (2023). [slide]
- "CompoDiff: Versatile Composed Image Retrieval With Latent Diffusion", Yonsei University (2023). [slide]
- "Probabilistic Image-Text Representations", Sogang University (2023). [slide]
- "ECCV Caption: Correcting False Negatives by Collecting Machine-and-Human-verified Image-Caption Associations for MS-COCO", NAVER and Sogang University (2022). [slide]
- "Towards Reliable Machine Learning: Challenges, Examples, Solutions", UNIST AIGS (2022). [slide]
- "Tutorial on Shortcut learning in Machine Learning: Challenges, Analysis, Solutions" at FAccT 2022. [ tutorial homepage | slide | video ]
- "Towards Reliable Machine Learning", KAIST and SNU (2022). [slide]
- "Shortcut learning in Machine Learning: Challenges, Examples, Solutions", POSTECH AI Research (PAIR) ML Winter Seminar 2022. [slide]
- "Realistic challenges and limitations of AI", University of Seoul (2021). [slide]
- "Mitigating dataset biases in Real-world ML applications", NAVER and NAVER Labs Europe (2021). [slide]
- "Limits and Challenges in Deep Learning Optimizers", UNIST (2021). [slide]
- "Towards better cross-modal learning by Probabilistic embedding and AdamP optimizer", UAB CVC (2021). [info] [slide]
- "AdamP: Slowing Down the Slowdown for Momentum Optimizers on Scale-invariant Weights", KSIAM (2021). [slide]
- "Towards Few-shot Font Generation", Seoul University and NAVER (2021). [slide]
- "Probabilistic Embeddings for Cross-modal Retrieval", SNU AI Institute (AIIS) Retreat. [slide]
- "Learning De-biased Representations with Biased Representations", NAVER (2020). [slide]
- "Reliable Machine Learning in NAVER AI", Yonsei University (2020). [slide]
- "Toward Reliable Machine Learning", omnious and nota (2020). [slide]
- "Reliable Machine Learning", NAVER CVPR 2020 sponser event. [program] [slide] [video]
- "Neural Architectures for Music Representation Learning", NAVER (2020). [slide]
- "Learning generalizable representations with CutMix and ReBias", NAVER Labs Europe (2019).
- "An empirical evaluation on the generalizability of regularization methods", ICML 2019 Expo Talk: Recent Work on Machine Learning at NAVER. [slide]
- "Recent works on deep learning robustness in Clova AI", ICLR 2019 Expo Talk: Representation Learning to Rich AI Services in NAVER and LINE.
- "Recommendation system in the real world", Deepest Summer School 2018. [slide]
Teaching
- Princeton AI4All Instructor, 2025
- KAIST Introduction to Big Data, TA, 2015
- KAIST EE (Electrical Engineering) Laboratory, TA, 2014
Code and Data
Datasets
- CUB v2 and OpenImages 30k [C5] [J2]: These datasets were designed and collected for the WSOL evaluation project. We newly collected bird images for CUB v2 (200 classes) and re-organize OpenImages V5 for OpenImages 30k (100 classes)
- Biased MNIST, 9-Class ImageNet and ImageNet cluster labels [C6]: We proposed these datasets for measuring how ML models can be generalized to bias shift. Biased MNIST is a synthetic dataset based on MNIST, while each image has background colors which highly correlates with the labels (controllable). ImageNet-9 contains 9 super-classes (dog, cat, frog, turtle, bird, monkey, fish, crab, insect) and 57k training samples. We also proposes "unbiased accuracy" by using cluster labels (K=9), which empicially matches to Shell, Grass, Close-up, Eye, Human, Sand and Mammal.
- CUB Caption [C11]: CUB was not majorly used for image-text matching (ITM) retrieval. However, while doing the PCME project, we proposed to use the CUB dataset as a ITM benchmark for measuring the impact of many-to-many correspondence; if an image and a description are in the same class, then we treat it as "positive" otherwise "negative". We carefully devide the training-validation (150 classes) and test splits (50 classes) following Xian et al. 2017.
- ECCV Caption [C21]: Although CUB Caption can evaluate the impact of many-to-many correspondence in ITM, this dataset is still "synthetic". For a more practical usage, we proposed the ECCV Caption benchmark, by correcting the false negatives (FNs) in the MS-COCO Caption dataset. By machine and human annotators, we collected x8.47 positive images and x3.58 positive captions compared to the original COCO Caption.
- RoCOCO [W9]: Is an ITM model robust to a malicious manipulation on captions or images? Here, we investigated the impact of altered captions (same concept, different concept, rand voca attack, and dangerous word) and mixed images. Even state-of-the-art ITM models showed substantial performance degradations on our benchmark.
Softwares
-
Few-shot Font Generation Benchmark.
- Song Park, Sanghyuk Chun
- open source. code
- Graphit: A Unified Framework for Diverse Image Editing Tasks.
- You can install my softwares [C9] [C21] via pip by following commands:
pip install adamp pip install eccv_caption
Industry Experience
NAVER AI Lab (2018 ~ 2025)
-

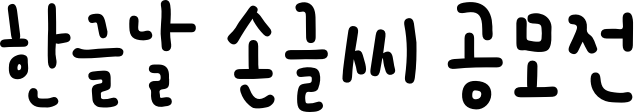
 Hangul Handwriting Font Generation
Hangul Handwriting Font GenerationDistributed at 2019 Hangul's day (한글날), [Full font list]
- Hangul (Korean alphabet, 한글) originally consists of only 24 sub-letters (ㄱ, ㅋ, ㄴ, ㄷ, ㅌ, ㅁ, ㅂ, ㅍ, ㄹ, ㅅ, ㅈ, ㅊ, ㅇ, ㅎ, ㅡ, ㅣ, ㅗ, ㅏ, ㅜ, ㅓ, ㅛ, ㅑ, ㅠ, ㅕ), but by combining them, there exist 11,172 valid characters in Hangul. For example, "한" is a combination of ㅎ, ㅏ, and ㄴ, and "쐰" is a combination of ㅅ, ㅅ, ㅗ, ㅣ, and ㄴ. It makes generating a new Hangul font be very expensive and time-consuming. Meanwhile, since 2008, Naver has distributed Korean fonts for free (named Nanum fonts, 나눔 글꼴).
- In 2019, we developed a technology for fully-personalized Hangul generation only with 152 characters, and released 109 user handwriting fonts. Details for the generation technique used for the service was presented in Deview 2019.
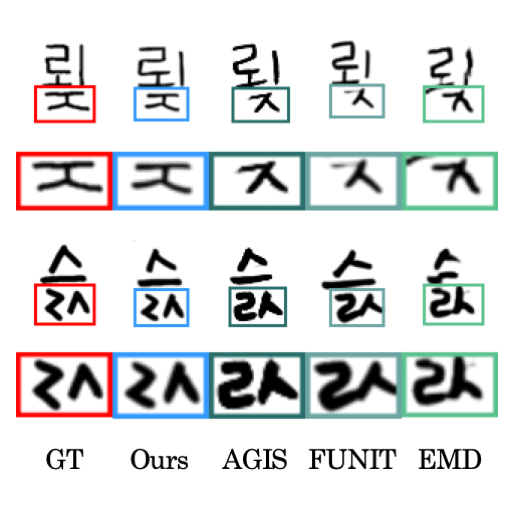
- This work was also extended to the few-shot generation based on the compositionality. See the papers in AI for Content Creation Workshop (AICCW) at CVPR 2020 (short paper), ECCV 2020 (full paper), AAAI 2021, ICCV 2021, and journal extension.
- [BONUS] You can play with my handwriting.
-

Example emoji from LINE sticker shop. Emoji Recommendation (LINE Timeline)Deployed in Jan. 2019
- LINE is a major messenger player in east asia (Japan, Taiwan, Thailand, Indonesia, and Korea). In the application, users can buy and use numerous emoijs a.k.a. LINE Sticker.
- In this project, we recommended emojis to users based on their profile picture (cross-domain recommendation).
- I developed and researched the entire pipeline of the cross-domain recommendation system and operation tools.
-
Mentees / Short-term post-doctoral collaborators / Internship students
Topics: Reliable ML Vision-Language Modality-specific tasks Generative models Other topics
- _ Junwon Lee (KAIST, 2025) [SelVA] -- AVL representation learning
- _ Sehyun Kwon (Seoul National University, 2024) -- VL representation learning
- _ Jaeyoo Park (Seoul National University, 2024) [W12] -- VL representation learning
- _ Jungin Park (Visiting researcher, 2024) -- VL representation learning
- _ Yujin Jeong (Korea University, 2024) [C33/W10] -- AVL representation learning
- _ _ Heesun Bae (KAIST, 2023) -- VL representation learning under noisy environment
- _ Jungbeom Lee (Visiting researcher, 2023) [C28] -- VL representation learning
- _ Eunji Kim (Seoul National University, 2022) -- XAI + Probabilistic Machine (the internship project is published at ICML 2023 [paper])
- _ Jaehui Hwang (Yonsei University, 2022) [C30] -- Adversarial robustness and XAI
- _ Chanwoo Park (Seoul National University, 2021-2022) [C22] -- Deep learning theory
- _ Gyeongsik Moon (Visiting researcher, 2022) [W7] -- Semi-supervised learning for 3D Human Mesh Estimation
- _ Hongsuk Choi (Visiting researcher, 2022) [W7] -- Semi-supervised learning for 3D Human Mesh Estimation
- _ _ Seulki Park (Seoul National University, 2022) [W9] -- VL robustness benchmark
- _ Saehyung Lee (Seoul National University, 2021-2022) [C19] -- Data condensation
- _ Sangwon Jung (Seoul National University, 2021-2023) [C18] [C19] -- Fairness with not enough group labels, group fairness
- _ Luca Scimeca (A short-term post-doctoral collaborator, 2021) [C16] [C14] -- Understanding shortcut learning phenomenon in feature space
- _ Michael Poli (KAIST, 2021) [C14] [C16] -- Neural hybrid automata
- _ Hyemi Kim (KAIST, 2021) -- Test-time training for robust prediction
- _ Jun Seo (KAIST, 2021) -- Self-supervised learning
- _ Song Park (Yonsei University, 2020-2021) [C8/W6] [C12] [A4] [J2] -- Few-shot font generation
- _ Hyojin Bahng (Korea University, 2019) [C6] -- De-biasing
- _ Junsuk Choe (Yonsei University, 2019) [C5] [J1] -- Reliable evaluation for WSOL
- _ Naman Goyal (IIT RPR, 2019) -- Robust representation against shift
- _ Minz Won (Music Technology Group, Universitat Pompeu Fabra, 2018-2019) [W2] [W4] [A2] [C4] -- Audio representation learning
- _ Byungkyu Kang (Yonsei University, 2018) [C2] -- Image-to-image translation and style transfer
- _ Jang-Hyun Kim (Seoul National University, 2018) [A1] -- Audio representation learning
- _ Jisung Hwang (University of Chicago, 2018) [W1] -- Adversarial robustness
- _ Younghoon Kim (Seoul National University, 2018) [W1] -- Adversarial robustness
Kakao Advanced Recommendation Technology (ART) team (2016 ~ 2018)
-
 Recommender Systems (Kakao services)
Recommender Systems (Kakao services)Feb. 2016 - Feb. 2018
- I developed and maintained a large-scale real-time recommender system (Toros [PyCon Talk] [AI Report]) for various services in Daum and Kakao. I mainly worked with content-based representation modeling (for textual, visual, and musical data), collaborative filtering modeling, user embedding, user clustering, and ranking system based on Multi-armed Bandit.
- Textual domain: Daum News similar article recommendation, Brunch (blog service) similar post recommendation, Daum Cafe (community service) hit item recommendation.
- Visual domain: Daum Webtoon and Kakao Page similar item recommendation, video recommendation for a news article (cross-domain recommendation).
- Audio domain: music recommendation for Kakao Mini (smart speaker), Melon and Kakao Music.
- Online to offline: Kakao Hairshop style recommendation.
-
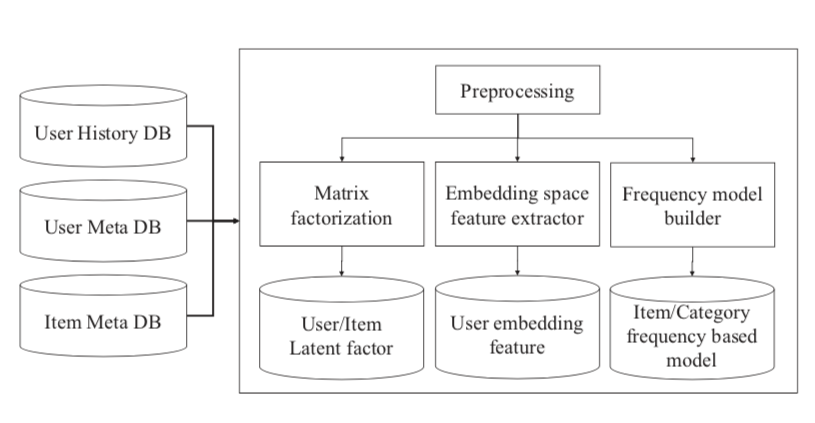
System overview. Personalized Push Notification with User History (Daum, Kakao Page)Deployed in 2017
- The mobile push service (or alert system) is widely-used in mobile applications to attain a high user retention rate. However, a freqeunt push notification makes a user feel fatigue, resulting on the application removal. Usually, the push notification system is a rule-based system, and managed by human labor. In this project, we researched and developed a personalized push notification system based on user activity and interests. The system has been applied to Daum an Kakao Page mobile applications. More details are in our paper.
-
 Large-Scale Item Categorization in e-Commerce (Daum Shopping)
Large-Scale Item Categorization in e-Commerce (Daum Shopping)Deployed in 2017
- An accurate categorization helps users to search desired items in e-Commerce based on the category, e.g., clothes / shoes / sneakers. However, the categorization is usually performed based on rule-based systems or human labor, which leads to low coverage of categorized items. Even the automatic item categorization is difficult due to its web-scale data size, the highly unbalanced annotation distribution, and noisy labels. I developed a large-scale item categorization system for Daum Shopping based on a deep network, from the operation tool to the categorization API.
Internship
-
 Research internship (Naver Labs)
Research internship (Naver Labs)Aug. 2015 - Dec. 2015
- During the internship, I implemented batch normalization (BN) to AlexNet, Inception v2 and VGG on ImageNet using Caffe. I also researched batch normalization for sequential models, e.g., RNN using Lua Torch.
-
 Software engineer (IUM-SOCIUS)
Software engineer (IUM-SOCIUS)Jun. 2012 - Jan. 2013
- I worked as web developer at IUM-SOCIUS. During the internship, I developed and maintained internal batch services (JAVA spring batch), internal statistics service (Python Flask, MongoDB), internal admin tools (Python Django, MySQL), and main service systems (JAVA spring, Ruby on Rails, MariaDB).
Education and Career
-
 (2025.07 - Now) Ph.D.
(2025.07 - Now) Ph.D.
Computer Science, Princeton University
-
 (2014.03 - 2016.02) M.S.
(2014.03 - 2016.02) M.S.
School of Electrical Engineering, KAIST
-
(2009.03 - 2014.02) B.S.
School of Electrical Engineering and School of Management Science (double major), KAIST
Career
-
 (2020.10 - 2025.07) Lead research scientist
(2020.10 - 2025.07) Lead research scientist
Leader of ML Research, NAVER AI Lab
-
(2019.10 - 2019.12) Lead research scientist
Visiting researcher at Naver Labs Europe
-
(2018.02 - 2020.09) Research scientist
NAVER CLOVA
-
(2016.02 - 2018.02) Research engineer
Advanced recommendation team (ART), Kakao
-
(2015.08 - 2015.12) Research internship
-
(2012.06 - 2013.01) Software engineering internship
IUM-SOCIUS